
AI新工具(20240315) Follow-Your-Click用户通过点击图像的特定部分实现域区图像动画
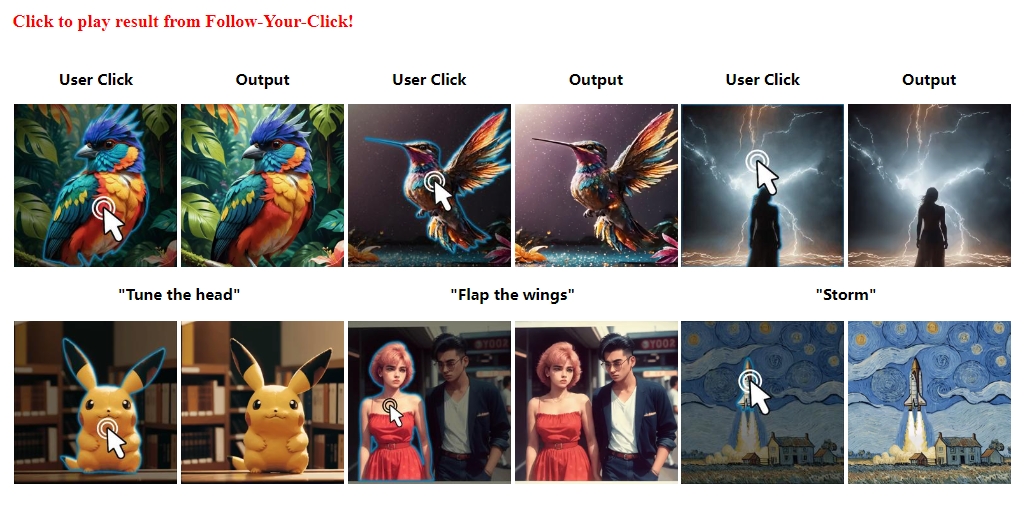
✨ 1: Follow-Your-Click
用户通过点击图像的特定部分实现域区图像动画

Follow-Your-Click 是一个开放领域的区域性图像动画创作工具,它可以通过简短的提示语实现图像中特定区域的动画效果。这种功能允许用户通过点击图像的特定部分并输入简短的指令(例如“微笑”、“拍打翅膀”或“运行”等),即可让图像中对应的部分产生动画,如让人物的脸上露出微笑,或是让鸟儿拍打翅膀。
地址:https://follow-your-click.github.io/
✨ 2: CoPa
先进的机器人操作框架

CoPa(Robotic Manipulation through Spatial Constraints of Parts),简单来说,是一个先进的机器人操作框架。它的核心在于利用大型基础视觉-语言模型(例如GPT-4V)中嵌入的常识性知识,以无需特定训练的方式,处理和执行各种复杂的、在开放环境中的任务指令和物体操控。这样的设计减少了对大规模数据集训练的依赖,并提高了机器人应对未知任务和物体的能力。
地址:https://copa-2024.github.io/
✨ 3: FineControlNet
通过空间控制输入和文本描述来控制图像生成的方法

FineControlNet是一个用于图像生成的官方Pytorch实现,旨在提供细粒度的文本控制。用户可以通过空间控制输入(如2D人体姿势)和特定实例的文本描述来控制图像实例的形式和纹理。FineControlNet支持简单的线条绘制或复杂的人体姿势作为空间输入,并确保实例与环境之间的自然互动和视觉协调。该工具借鉴了Stable Diffusion的质量和泛化能力,并提供了更多的控制选项。FineControlNet扩展了ControlNet1.1的环境,支持文本细粒度控制以及OpenPose姿势、Canny边缘、M-LSD线条、HED边缘和草图等几何控制。
地址:https://github.com/SamsungLabs/FineControlNet
✨ 4: VLOGGER
从单个人物图像生成文本和音频驱动的说话视频

VLOGGER是一种文本和音频驱动的人体视频生成方法,能够从一个人的单个输入图像中生成说话的人类视频。该方法基于最近生成扩散模型的成功,包括1) 随机的人体到3D运动扩散模型,以及2) 一种新颖的基于扩散的架构,将文本到图像模型与时间和空间控制相结合。这种方法使得生成长度可变的高质量视频变得容易控制,通过对人脸和身体的高级表示。与以往方法不同的是,我们的方法不需要为每个人进行训练,也不依赖于人脸检测和裁剪,生成完整的图像(而不仅仅是脸部或嘴唇),考虑到了正确合成沟通的人的广泛情景(例如,可见的躯干或不同的主体身份)。
我们在三个不同的基准上评估了VLOGGER,并展示了所提出的模型在图像质量、身份保留和时间一致性方面超越了其他最先进的方法。我们收集了一个新的多样化数据集MENTOR,比以前的数据集大一个数量级(2,200小时和800,000个身份,以及一个测试集,包含120小时和4,000个身份),我们在此数据集上进行了训练和消融我们的主要技术贡献。我们报告了VLOGGER在多个多样性指标方面的性能,显示我们的架构选择有利于在规模上训练公平和无偏见的模型。
地址:https://enriccorona.github.io/vlogger/
✨ 5: StreamMultiDiffusion
实时互动生成多文本到图像的区域语义控制工具

StreamMultiDiffusion是一个实时、互动、基于用户指定区域文本提示的多文本到图像的生成工具。换句话说,它允许用户使用“绘画意义”而不是“绘画颜色”的画笔来进行绘制。这意味着用户可以通过输入文本提示来控制图像的特定区域生成特定的内容,从而实现更加细致和个性化的图像创作过程。
地址:https://github.com/ironjr/StreamMultiDiffusion
更多AI工具,参考国内AiBard123,Github-AiBard123

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621