
AI新工具(20240729) 六个开源的PDF转Markdown项目
✨ 1: gptpdf
gptpdf 是一个利用VLLM解析PDF为Markdown的工具,几乎完美支持数学公式、表格等。

GPTPDF 是一个使用视觉大模型(如 GPT-4o)将 PDF 文件解析成 Markdown 文件的工具。它主要用于高效地解析 PDF 文档中的排版、数学公式、表格、图片、图表等内容,并将这些内容转换为结构化的 Markdown 格式。其显著特点是简单且成本低,每页平均费用为 $0.013。
地址:https://github.com/CosmosShadow/gptpdf
✨ 2: marker
Marker是一款将PDF快速精准转换为Markdown的工具,支持多种文档格式和语言。
Marker是一款能够快速且准确地将PDF转换为Markdown的工具。它支持多种类型的文档(针对书籍和科学论文进行了优化),支持所有语言,并且能够去除页眉、页脚及其他杂乱信息。此外,它还能正确格式化表格和代码块,并提取图像保存为Markdown。同时,Marker将大多数的公式转换为LaTeX格式,适用于GPU、CPU或MPS环境。
地址:https://github.com/vikparuchuri/marker
✨ 3: PDF-Extract-Kit
PDF-Extract-Kit 提供高质量PDF内容提取,支持布局检测、公式识别和OCR功能
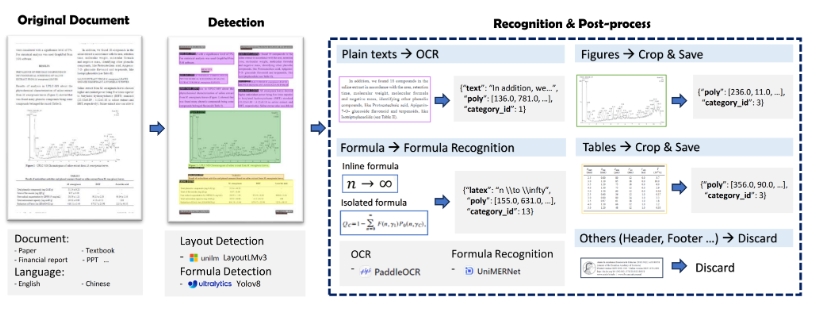
- 版面检测:使用 LayoutLMv3 模型进行区域检测,如检测图片、表格、标题、文本等。
- 公式检测:使用 YOLOv8 模型检测公式,包括行内公式和独立公式。
- 公式识别:使用 UniMERNet 进行公式识别。
- 光学字符识别 (OCR):使用 PaddleOCR 进行文本识别。
地址:https://github.com/opendatalab/PDF-Extract-Kit
✨ 4: zeroX
Zerox OCR 是一种经济高效且准确的文档OCR工具,适用于AI数据处理。

Zerox OCR 是一种极其简便的方法,用于将文档进行光学字符识别(OCR)并方便人工智能进行后续处理。鉴于文档往往包含复杂布局、表格、图表等,视觉模型在处理这些内容时尤其有效。
基本逻辑如下: 提供一个 PDF 文件(URL 或文件缓冲区)。 将 PDF 转换成一系列图像。 将每个图像传给 GPT,让其生成 Markdown 格式的文本。 聚合所有响应,并返回 Markdown 格式的结果。
地址:https://github.com/getomni-ai/zeroX
✨ 5: omniparse
OmniParse是一个将各种非结构化数据转换为结构化、适用于生成式AI(LLM)应用的平台。

OmniParse 是一个数据解析平台,旨在将各种非结构化数据转换为适用于生成式AI(GenAI)应用的结构化数据。无论是文档、表格、图像、视频、音频文件,还是网页,OmniParse 都能对其进行处理,使其变得干净、结构化,并为诸如 RAG(Retrieval-Augmented Generation)和细调等AI应用做好准备。
- 完全本地化,无需外部API
- 支持多达 20 种文件类型
- 将文档、多媒体和网页转换为高质量的结构化 Markdown
- 支持表格提取、图像提取与标注、音频/视频转录、网页爬取
- 通过 Docker 和 Skypilot 轻松部署
- 兼容 Colab
- 交互式 UI 由 Gradio 提供支持
地址:https://github.com/adithya-s-k/omniparse
✨ 6: MinerU
MinerU 是一个开源的高质量数据提取工具,支持多种文件格式
MinerU 是一个一站式、开源的高质量数据提取工具,主要包括以下两个核心功能模块:
Magic-PDF
- 功能介绍:Magic-PDF 能将 PDF 文档转换为 Markdown 格式,可以处理本地存储或支持 S3 协议的对象存储中的文件。
- 主要特色:
- 支持多种前端模型输入
- 自动去除页眉、页脚、脚注和页码
- 保留文档原有的结构和格式,包括标题、段落、列表等
- 提取并显示图片和表格
- 将公式转换为 LaTeX 格式
- 自动检测和转换乱码 PDF 文档
- 兼容 CPU 和 GPU 环境
- 可在 Windows、Linux 和 macOS 平台上使用
Magic-Doc
- 功能介绍:Magic-Doc 能将网页或多格式电子书转换为 Markdown 格式。
- 主要特色:
- 网页提取:跨模态精确解析文本、图片、表格和公式信息
- 电子书文档提取:支持包括 epub、mobi 在内的多种文档格式,完美适配文本和图片
- 语言类型识别:精确识别176种语言
地址:https://github.com/opendatalab/MinerU
更多AI工具,参考国内AiBard123,Github-AiBard123 公众号:每日AI新工具

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621