
AI新工具(20240807) Lumina-mGPT图像生成;清华大学研发的首个开源预训练文本生成视频模型;Medical SAM 2实现2D和3D医学图像分割
✨ 1: Lumina-mGPT
Lumina-mGPT是一种多模态自回归模型,尤其擅长将文本描述生成灵活逼真的图像。

Lumina-mGPT是一系列多模态自回归模型,能够处理多种视觉和语言任务,其中尤为擅长从文本描述中生成灵活的真实感图像。该模型家族由Alpha-VLLM团队研发,适用于多种多模态生成和理解任务。
图像生成(Image Generation): 从文本描述生成对应的高质量图像。例如,输入一段描述“狗在玩水,背景有瀑布”的文本,Lumina-mGPT可以生成符合描述的图像。
图像理解(Image Understanding): 对图像进行详细描述。例如,输入一张图像,模型可以生成该图像的详细文字描述。
多功能任务(Omni-SFT): 支持多种任务,如图像深度估计、图像到图像的转换、图像编辑等。用户可以在单个界面中切换不同任务。
地址:https://github.com/Alpha-VLLM/Lumina-mGPT
✨ 2: CogVideo
CogVideo 是清华大学研发的首个开源预训练文本生成视频模型,CogVideoX 系列进一步增强了视频生成的能力。

CogVideo是清华大学开发的一种用于文本生成视频的预训练模型,采用了Transformer结构。它是第一个公开的预训练文本到视频生成模型,已在ICLR'23 上正式发布。CogVideo可以生成高帧率的视频,具备较强的生成能力。而CogVideoX是CogVideo系列视频生成模型的一个开源版本,支持更大规模的参数和更多的视频生成功能。
地址:https://github.com/THUDM/CogVideo
✨ 3: WiseFlow
WiseFlow 是一个智能信息提取工具,可从多个来源自动分类并上传数据到数据库。
WiseFlow 是一个敏捷的信息提取工具,能够从各种来源(如网站、微信公众号、社交媒体平台)中,根据预定义的关注点提炼信息,自动对标签进行分类,并上传到数据库。其主要功能是帮助用户节省时间、过滤无关信息,并组织重点关注的信息。
地址:https://github.com/TeamWiseFlow/wiseflow
✨ 4: Medical SAM 2
Medical SAM 2利用SAM 2框架,实现2D和3D医学图像分割。
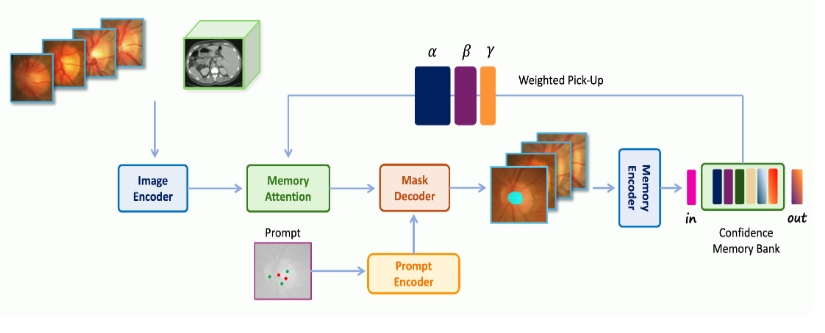
Medical SAM 2(简称MedSAM-2)是一种高级图像分割模型,基于SAM 2框架,专门用于处理2D和3D的医疗图像分割任务。该模型通过把医疗图像当作视频来分割,展现了较为突出的性能。具体细节请参见论文:Medical SAM 2: Segment Medical Images As Video Via Segment Anything Model 2。
地址:https://github.com/MedicineToken/Medical-SAM2
✨ 5: Structured Outputs in the API
OpenAI引入API结构化输出

openai正在API中引入了Structured Outputs。这是一项新功能,旨在确保模型生成的输出能够准确匹配由开发人员提供的JSON模式。这对于以API构建可靠应用程序的开发人员来说是一个重要的里程碑,因为此功能将提高模型的可靠性。Structured Outputs 可以通过函数调用或在响应格式中使用 JSON Schema。
除了可以通过函数调用 Structured Outputs,还可以通过响应格式参数中的 JSON Schema 使用。这对于最新发布的 GPT-4o 型号适用,包括 gpt-4o-2024-08-06 和 gpt-4o-mini-2024-07-18。开发人员在使用此功能时需要注意以下几点限制和限制条件,包括只允许使用一部分JSON模式,对新模式的第一次请求可能会产生额外延迟,以及模型拒绝请求或在生成一定数量的 tokens 后结束可能会导致模型无法按模式执行。Structured Outputs 在 API 中已经发布,并且支持函数调用和响应格式两种使用方式。
地址:https://openai.com/index/introducing-structured-outputs-in-the-api/
更多AI工具,参考国内AiBard123,Github-AiBard123 公众号:每日AI新工具

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621