
AI新工具(20241114) RMBG发布v2.0一键去背景模型效果炸裂;大语言模型的智能视频字幕;生成高质量的虚拟试穿视频Fashion-VDM
✨ 1: RMBG v2.0
RMBG v2.0是一个先进的图像背景去除模型,适用于多种商业场景。

RMBG v2.0(BRIA背景去除模型)是由BRIA AI开发的一款先进的背景去除模型,旨在高效地将前景与背景分离,适用于多种类别和图像类型。该模型经过精心挑选的数据集训练而成,涵盖了通用库存图像、电子商务、游戏和广告内容,适合商业用途,支持大规模企业内容创作。其准确性、效率和灵活性与市场上领先的模型不相上下,尤其在内容安全、法律合规性和偏见缓解方面表现突出。
RMBG v2.0是一个二分类图像分割模型,使用了超过15,000张高质量、高分辨率的手动标注图像进行训练,确保了数据的多样性,包括不同性别、种族和残疾人群的平衡。该模型在各种场景中展现了其适应性,尤其在前景和背景的处理上,提供了精准的分割效果。
该模型架构基于BiRefNet,并结合了BRIA提供的专有数据集和训练方案,以提升背景去除任务的准确性和有效性。RMBG v2.0目前作为一个开源模型发布,允许非商业用途,但商业使用需与BRIA签订协议获取许可。
使用该模型只需简单的Python库调用,使用者可以方便地对图像进行背景去除。
地址:https://huggingface.co/briaai/RMBG-2.0
✨ 2: VideoCaptioner
VideoCaptioner(卡卡字幕助手)是一款基于大语言模型的智能视频字幕处理软件,支持全流程字幕生成与优化。

VideoCaptioner是一款基于大语言模型(LLM)的智能视频字幕处理软件,旨在简化视频字幕的生成与优化流程。用户只需简单操作,无需高性能设备即可生成精准字幕。软件具备智能断句、校正、优化及翻译等多项功能,能够为视频配上自然流畅、专业的字幕效果。
地址:https://github.com/WEIFENG2333/VideoCaptioner
✨ 3: Region-Aware Text-to-Image Generation
该研究提出了一种区域感知的文本到图像生成方法,通过硬绑定和软细化实现精确的布局组合。

Region-Aware Text-to-Image Generation(区域感知的文本到图像生成)是一种基于区域描述的生成方法,旨在实现精确的布局组合。该方法通过“区域硬绑定”(Regional Hard Binding)和“区域软细化”(Regional Soft Refinement)两个子任务来处理多区域生成的问题。首先,通过区域硬绑定确保每个区域的描述得到正确执行,然后通过区域软细化对各个区域的细节进行整体调整,增强了相邻区域的交互性。此外,该方法支持“重涂”(repaint),用户可以在最后生成图像中修改特定区域而不影响其他部分,而无需额外的修复模型。
区域感知的文本到图像生成方法提供了灵活且精准的控制,适用于多种需要图像创作和编辑的场景。
地址:https://github.com/NJU-PCALab/RAG-Diffusion
✨ 4: Fashion-VDM
Fashion-VDM是一种视频扩散模型,用于生成高质量的虚拟试穿视频,保持人物特征和动态一致性。
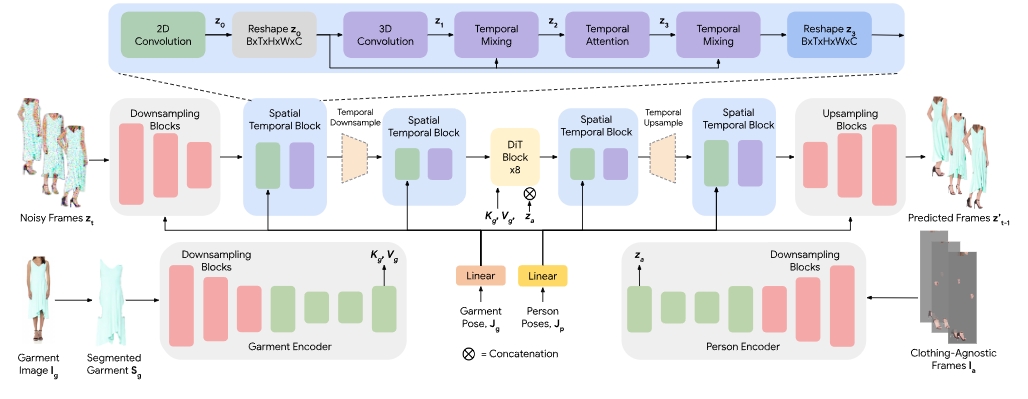
Fashion-VDM是一种用于生成虚拟试穿视频的视频扩散模型(VDM)。该模型的主要目标是结合输入的服装图像和个人视频,生成高质量的试穿视频,同时保持人的身份和动作。虽然基于图像的虚拟试穿已经取得了显著成果,但现有的视频虚拟试穿方法在服装细节和时间一致性方面仍显不足。因此,Fashion-VDM提出了一种基于扩散的架构,采用分类器无关引导策略以增加对条件输入的控制,并采用渐进式的时间训练策略,以实现单次处理64帧、512像素的视频生成。
该模型的架构通过对噪声视频进行处理,提取人物姿态和不依赖于服装的帧。服装图像也经过处理以提取服装分割和服装姿态。在训练过程中,Fashion-VDM经历了多个逐步增加帧长度的阶段,先对图像模型进行预训练,然后再针对视频数据集进行时空层的训练。
此外,Fashion-VDM还引入了分割分类器无关引导策略,使其能够对多个条件信号进行独立控制。最终的实验显示,这种方法在视频虚拟试穿领域设置了新的最先进记录。
尽管Fashion-VDM在生成虚拟试穿视频方面表现出色,但模型仍存在一些局限性,比如可能出现的身体形态不准确、伪影和服装遮挡区域的不正确细节等。未来的工作可能会考虑多服装条件和个体化定制,以提高服装和人物的一致性。
地址:https://johannakarras.github.io/Fashion-VDM/
✨ 5: ebook2audiobook
ebook2audiobook是一款将电子书转换为有声书的工具,支持多语言和语音克隆功能。
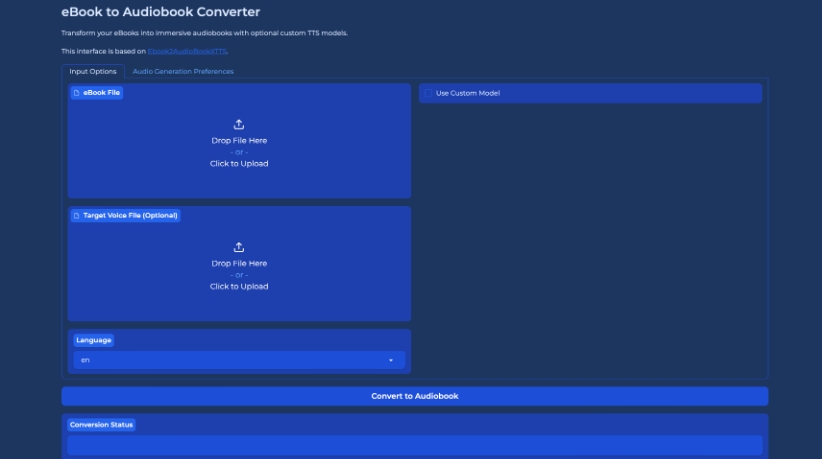
ebook2audiobook 是一款用于将电子书(eBooks)转换为有声书(audiobooks)的工具,支持章节划分和元数据处理。它结合了 Calibre 和 Coqui XTTS 技术,能够生成高质量的文本转语音 (TTS) 结果。该工具还支持可选的语音克隆和多语言转换,用户可以根据需要选择使用自己的语音文件。
地址:https://github.com/DrewThomasson/ebook2audiobookXTTS
更多AI工具,参考国内AiBard123,Github-AiBard123 公众号:每日AI新工具

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621