
Large World Model
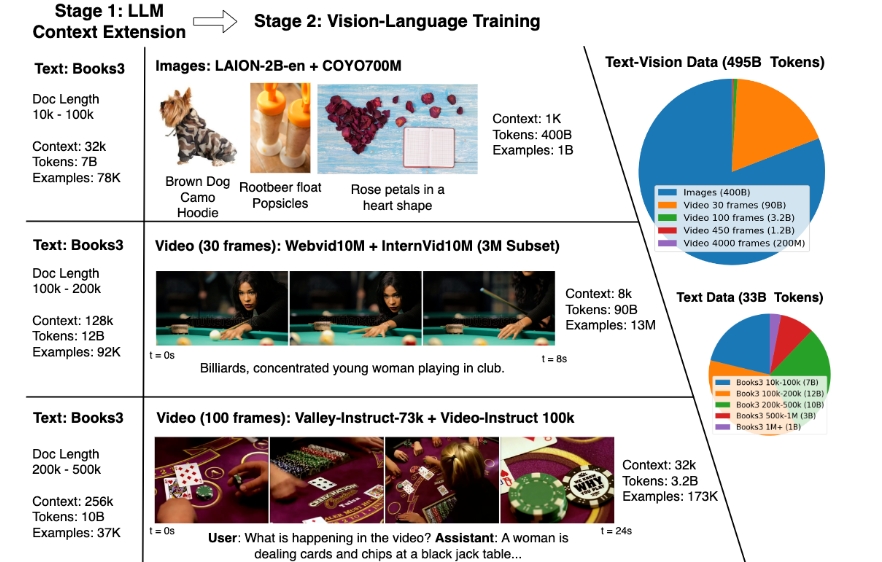
Large World Model(LWM)是一个通用的大环境多模态自回归模型,它利用了一个技术名为RingAttention,通过在大型的多样化视频和图书数据集上的训练,实现了对语言、图像和视频的理解与生成能力。
功能概述:
LWM主要解决的问题是,当前的语言模型在理解那些难以用言语描述的世界方面存在短板,并且在处理复杂、长篇任务时表现不佳。视频序列提供了语言和静态图像中缺失的宝贵时间信息,这对于与语言的联合建模而言十分有吸引力。这些模型可以发展对人类文本知识和物理世界的理解,为人类提供更广泛的AI能力。但是,从数百万个视频和语言序列的标记中学习面临着内存限制、计算复杂性和数据集有限等挑战。为了解决这些挑战,LWM整合了大量多样化视频和图书的数据集,使用RingAttention技术在长序列上可扩展地训练,并逐步将环境大小从4K增加到1M标记。
应用场景:
LWM可以在以下情况下使用:
-
知识检索与回答问题:LWM能够在1M的环境中准确地检索事实,这使其能够回答基于覆盖范围极广数据的复杂问题,例如,在长达一小时的YouTube视频中找到特定信息。
-
与图像的对话:LWM不仅能够理解和生成语言,还可以与图像“对话”。这意味着它可以理解图像内容,并根据图像内容生成文本回应。
-
从文本生成视频和图像:LWM能够将文本描述转换成图像或视频,这在内容创作、游戏开发和其他需要将文本想法可视化的领域具有巨大应用潜力。
使用条件:
由于LWM处理的任务涉及到大量的数据处理和高计算能力,通常它会在需要深入理解和生成基于语言、图像和视频的内容的复杂应用中被使用。例如,自动化内容创作、深度交互式学习系统、高级聊天机器人、以及需要理解和分析大型视频数据的研究和开发项目。
LWM是一个强大的多模态理解和生成工具,它通过结合语言、视频和图像数据,能够处理前所未有的大规模和复杂的AI任务,为开发更高级、更智能的应用打开了大门。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621