
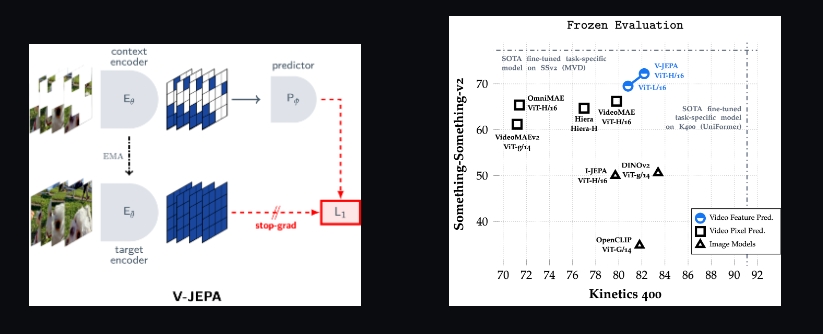
V-JEPA
V-JEPA(Video Joint Embedding Predictive Architecture)是由Meta AI研究团队开发的一个用于视频中自监督学习视觉表示的框架。简而言之,V-JEPA的目标是通过分析视频像素来学习有用的视觉特征,而不需要依赖预训练的图像编码器、文本、负样本、人类标注或像素级别的重构等常见方法。
V-JEPA功能简介
- 自监督学习: V-JEPA通过观看视频来进行自监督学习,意味着它不需要任何标记,如视频分类、目标检测等任务的人工标记数据。
- 预测在潜空间进行: 不同于那些直接在像素层面进行生成的方法,V-JEPA预测发生在潜空间,即它预测的是视频的中间表示而非直接的下一个帧。
- 高效的可移植特征: 经过预训练的V-JEPA模型能产生的视觉表示对下游任务(如视频和图像的分类、检测任务)非常有效,且使用时不需要修改模型的参数。
V-JEPA使用场景
考虑到其特性,V-JEPA在以下情形中特别有用:
- 大规模无标注视频数据的特征学习: 当手头有大量未标注的视频数据并且希望提取有用的视觉特征时,V-JEPA提供了一种有效学习这些特征的方法。
- 迁移学习: 由于V-JEPA学到的视觉表示的通用性,这些表示很适合作为其他视觉任务的预训练模型,特别是当这些任务的训练数据有限时。
- 增强现有模型: 在一些需要理解视频内容的应用中,如自动视频标注、内容推荐等,可以利用V-JEPA作为特征提取器来增强模型的性能。
V-JEPA提供了一种新颖的方法来从视频中无监督学习视觉表示。利用其强大的特性,V-JEPA在处理大规模未标记视频数据时表现尤为出色,能够有效地捕捉视频内容的丰富信息。无论是用于直接的视觉任务还是作为预训练模型进一步应用于其他视觉领域,V-JEPA都展示了巨大的潜力和灵活性。
Related Issues not found
Please contact @go2coding to initialize the comment

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621