
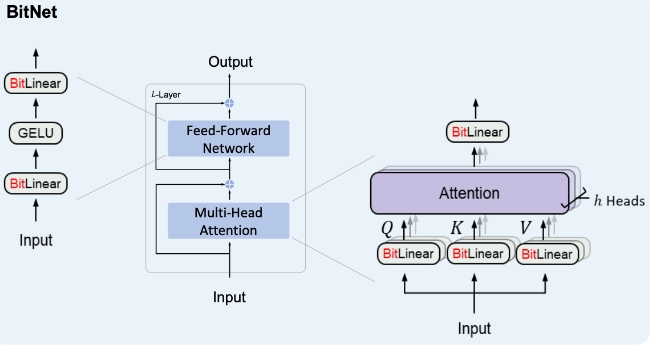
BitNet
BitNet是一种创新的深度学习架构,专为放大和优化大型语言模型而设计。它主要通过将常规线性投影(例如,PyTorch中的nn.Linear)替换为BitLinear模块来实现。这种替换使得模型能够以更低的内存占用和计算成本进行训练和推理,同时保持或甚至提高模型性能。
BitNet的核心功能包括:
-
BitLinear层:该层通过执行规范化、二值化和绝对最大值量化等一系列操作,实现了对数据的高效处理,大大减少了模型的参数量和计算复杂度。
-
BitNetTransformer:一个完整的Transformer实现,它不仅可用于处理文本数据,还可以处理图像、视频或音频数据。这得益于其结构中整合了多头注意力(MHA)和BitFeedforward层,同时包括残差连接和跳跃连接以优化梯度流。
-
BitAttention:这种注意力机制使用了BitLinear替代默认的线性投影,结合了多组查询注意力(Multi-Grouped Query Attention)机制,可以实现更快的解码速度和更长的上下文处理能力。
-
BitFeedForward:在图示中展示的前馈网络能够通过BitLinear和GELU激活函数,以及可选的dropout、层规范化等进一步增强模型性能。
BitNet在多种场景下都有应用前景,主要包括:
- 高效的大型语言模型(LLM)训练和推理:当资源有限但需要训练或部署大型模型时,BitNet可以提供一种经济高效的解决方案。
- 跨模态学习任务:BitNet的灵活性使其能够处理不同类型的数据,如文本、图像、视频和音频,适合执行跨模态学习任务。
- 实时处理和低延迟应用:BitNet的高效性能使其非常适合需要快速响应的应用,如在线翻译、实时内容审核等。
通过采用1-bit技术和创新的注意力机制,它不仅有望缩小模型的存储和计算需求,还能在保持甚至提升性能的前提下,推动深度学习模型的进一步发展和广泛应用。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621