
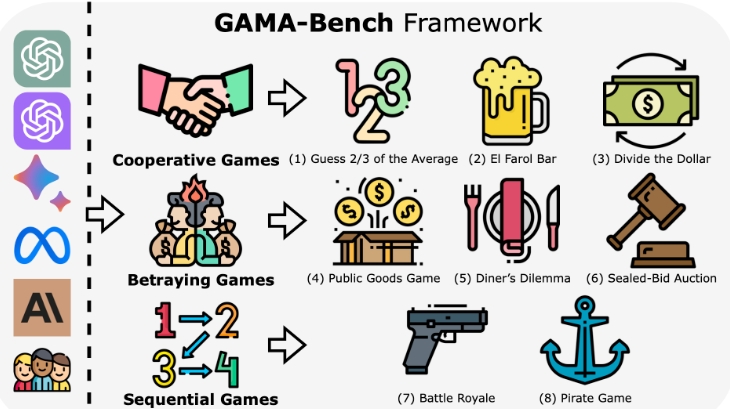
GAMABench
GAMABench是一个用于评估大型语言模型(LLMs)在多代理环境中决策能力的框架。它通过模拟游戏,将不同的语言模型置于相互互动的虚拟环境中,以测试它们的策略、应对和决策能力。以下是GAMABench的简单总结和在何种情况下使用的讲解:
可定制性:
- 模型配置:用户可以自定义模型API,通过在工具中指定OpenAI模型(如gpt-3.5-turbo或gpt-4)或其他支持的模型(如gemini系列),来创建不同的游戏场景。
- 游戏实例:通过简单的Python代码,可以配置游戏实例,设定玩家数量、游戏参数(如最小值、最大值、比率等),选择使用哪个版本的提示语,以及指定输出文件的名称。
负载和运行游戏:
- 指定测试用例:通过
main.py脚本中的代码,用户可以指定服务器参数,选择游戏(例如猜数字游戏),并运行多轮游戏实例,每轮完成后会记录并保存游戏结果。 - 加载和复用:支持加载之前保存的游戏实例数据,甚至可以在新的文件中继续游戏,无需从头开始。
模型指令和特殊玩家:
- 模型选择:用户可以指定单个模型或模型列表,以决定游戏中的玩家分别运行哪些模型。还可以通过指定特殊的字符串,来使某些玩家按固定模式回应。
- 包含真人玩家:
user模式允许真人通过终端参与与模型的交互游戏,为实验增加互动性。
提示重写与定制化:
- 自定义提示:GAMABench允许用户重写和定制游戏中的提示,使其更适合特定的测试需求或研究目标。
使用场景:
GAMABench可以用于多种研究和评估场景,主要包括:
- 评估LLMs的决策能力:通过在复杂的多代理环境中测试LLMs,研究者可以评估模型的策略、预测和决策能力。
- 算法和模型比较:通过制定标准化的游戏测试,研究者可以在统一的平台上比较不同LLMs的表现。
- 教育和学习:GAMABench提供自定义环境和互动游戏,对于教育者和学习者来说,是了解和探讨AI决策制作的有趣工具。
GAMABench是一个功能全面、高度可定制化的框架,适用于需要深入了解和评估大型语言模型在多代理交互环境中性能表现的场合。无论是研究者想要系统性评估LLMs的决策能力,还是教育工作者寻找实践工具,GAMABench都提供了丰富的功能和灵活的配置选项来满足不同用户的需求。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621