
Latte
Latte(Latent Diffusion Transformer for Video Generation)是一个采用潜在扩散模型和Transformer结合的视频生成技术。这项技术的主要目的是通过模型学习视频的分布,进而能够生成高质量的视频内容。其特点主要包括:
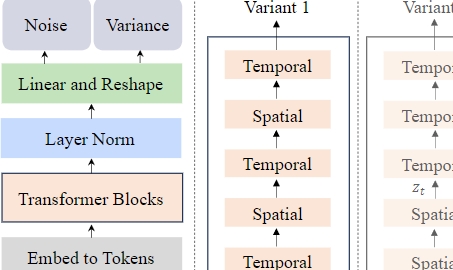
- 潜在空间的视频生成: Latte首先从输入视频中提取时空令牌(spatio-temporal tokens),然后使用一系列的Transformer模块来在潜在空间中建模视频分布。
- 高效变体: 为了能够处理从视频中提取的大量令牌,Latte引入了四种从分解输入视频的空间和时间维度的角度出发的高效变体。
- 生成质量的优化: 通过严格的实验分析,确定了Latte的最佳实践,包括视频剪辑补丁嵌入、模型变体、时间步类信息注入、时间位置嵌入和学习策略等,以提高生成视频的质量。
- 应用扩展性: Latte不仅在视频生成任务上表现出色,还扩展到了文本到视频生成(Text-to-Video,T2V)任务上,与最新的T2V模型具有可比的性能。
在什么情况下会使用Latte?
- 视频内容创建: 在媒体和娱乐行业中,当需要大量自动生成具有特定风格或者背景故事的视频内容时,可以考虑使用Latte来实现这一需求。
- 数据增强: 在机器学习领域,尤其是视频相关的任务(如视频分类、对象检测等),可使用Latte来生成视频数据,用于增强现有的训练数据集。
- 艺术与创意表达: 对于艺术家或创意工作者来说,Latte提供了一种新的方式来探索和实现自己的创意构想,通过输入特定的文本或视频片段,生成独特风格的视频作品。
- 教育和培训: 在教育领域,Latte可以用来创造教学视频或模拟训练场景,特别是在需要大量定制内容的情境中,如远程学习、模拟实验等。
Latte作为一种新型的视频生成技术,其结合了深度学习中的潜在扩散模型和Transformer架构,提供了一种高效且质量上乘的视频内容自动生成方法。无论你是从事视频内容制作、机器学习研究,还是艺术创作和教育培训,Latte都可以作为一个强大工具帮助你实现目标。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621