
Qwen1.5-MoE
Qwen1.5-MoE是一个使用混合专家模型(Mixture-of-Experts,MoE)架构的尖端人工智能模型。本文简要地用通俗语言解释了Qwen1.5-MoE的功能及其应用场景。
博客: https://qwenlm.github.io/blog/qwen-moe/ HF: https://huggingface.co/Qwen GitHub:https://github.com/QwenLM/Qwen1.5
Qwen1.5-MoE的功能和优点
-
效能匹敌7B模型,但参数激活量仅为三分之一:Qwen1.5-MoE仅激活了2.7亿个参数,却能够在性能上匹敌拥有70亿参数(7B)模型(如Mistral 7B和Qwen1.5-7B)。这意味着它在大幅节省资源的同时,还能提供顶级的模型表现。
-
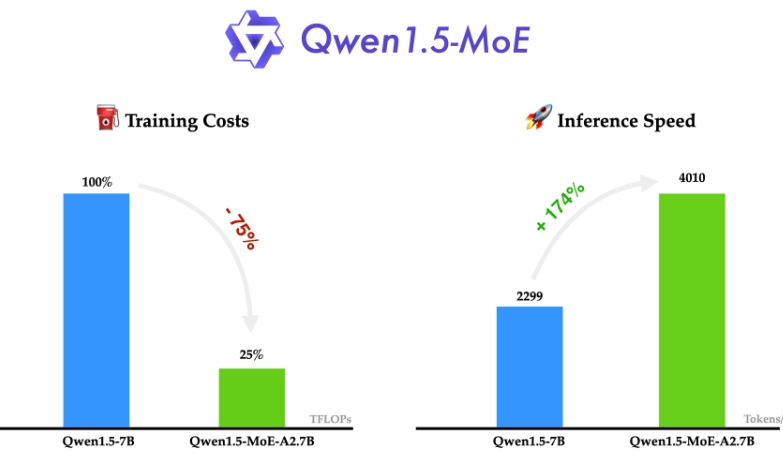
降低训练成本:与7B模型相比,Qwen1.5-MoE能够减少75%的训练费用,这对于需要在成本和效果之间寻找平衡的开发者来说是一个巨大的优势。
-
提高推理速度:Qwen1.5-MoE的推理速度比7B模型快约1.74倍。在处理大型数据或需要快速响应的应用场景中,这可以极大地提高用户体验。
-
精心设计的MoE架构:通过引入更多细粒度专家、改进的初始化方法(称为“upcycling”)以及共享和路由专家的路由机制,Qwen1.5-MoE优化了传统MoE的配置,提高了模型效率和灵活性。
使用场景
-
资源受限的研究与开发:对于那些计算资源有限但仍希望使用大型模型的研究者和开发者来说,Qwen1.5-MoE提供了一个可行的解决方案。它使得在不牺牲太多性能的情况下,以较低的成本和更快的速度进行模型训练和推理成为可能。
-
需要高效模型的应用:在那些对推理速度有着严格要求的应用中,Qwen1.5-MoE的高效性能表现尤其有价值。这包括但不限于实时语言翻译、自然语言处理、实时推荐系统等。
-
大规模多语言任务:由于Qwen1.5-MoE在多语言基准测试中表现出色,因此它非常适合处理涉及多种语言的任务,如跨语言的信息检索、机器翻译等。
Qwen1.5-MoE是一款性能强大、资源高效的混合专家模型,它将人工智能模型的规模和效率做到了精妙平衡。无论是在研究领域还是实际应用中,Qwen1.5-MoE都为用户提供了一种在有限资源下进行高效开发和推理的选择。随着技术的不断进步,我们有理由相信MoE模型将在未来的AI发展中扮演更加重要的角色。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621