
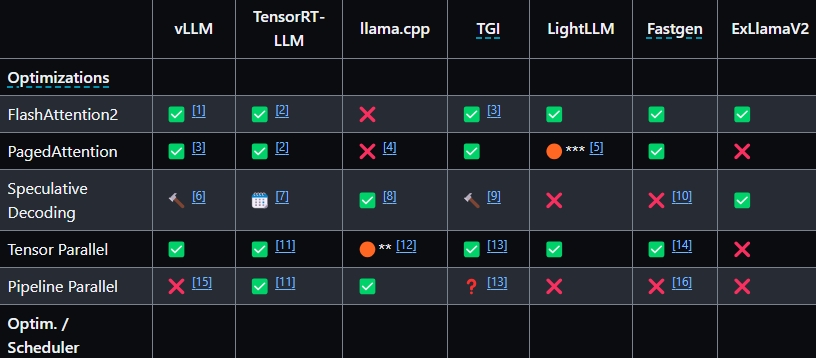
Open Inference Engines
Open Inference Engines(开放推理引擎)是一组专为不同应用场景设计的软件库,它们提供了通过优化模型来执行机器学习推理任务的能力。这些引擎专注于不同方面的优化,如处理速度、API兼容性、以及支持的特性等,以便在不同的硬件和软件环境中实现最佳性能。
以下是一些主要的Open Inference Engines及其功能:
- vLLM:专注于提供最优的吞吐量。
- TensorRT-LLM:Nvidia开发的高性能引擎,提供类似Pytorch的扩展API,适用于Nvidia Triton推理服务器。
- llama.cpp:无任何依赖的纯C++实现,优先支持苹果硅芯片。
- TGI(Text Generation Inference):HuggingFace开发的快速灵活的引擎,旨在实现高吞吐量。(源码可获取,但不完全开放)
- LightLLM:轻量级、快速、灵活的框架,旨在通过纯Python / Triton实现性能优化。
- DeepSpeed-MII / DeepSpeed-FastGen:Microsoft的高性能实现,包括最新的动态Splitfuse优化。
- ExLlamaV2:在现代消费级GPU上高效运行语言模型,实现了最新的量化方法EXL2。
在选择使用Open Inference Engines的情况下,主要考虑以下几点:
-
性能需求:不同引擎针对特定任务有不同的性能优化。比如,若需要高吞吐量,可能会选择vLLM或TGI。
-
硬件支持:根据你的硬件设备(如Nvidia GPU、苹果硅芯片)选择最优的引擎。比如,使用Nvidia硬件时,TensorRT-LLM可能是好选择。
-
API兼容性与易用性:一些引擎提供类似OpenAI的API,便于集成和使用。若项目已经在使用类似的API,选择兼容性好的引擎可以减少改动。
-
特性支持:比如,若需使用特殊的优化方法(如Speculative Decoding或FlashAttention2)或功能(如Beam Search或支持特定模型的引擎),则需要选择支持这些特性的引擎。
-
开放性:基于项目需要,可能偏好使用完全开源的解决方案。一些引擎如llama.cpp和ExLlamaV2提供更开放的许可证。
-
社区与支持:选择有活跃社区和良好文档支持的引擎,可以在遇到问题时快速找到解决方案。
Open Inference Engines为不同的机器学习推理任务提供了多样化的选择。根据你的具体需求,如性能、易用性、兼容性以及特性支持等,选择最适合你的项目的引擎。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621