
MuseTalk
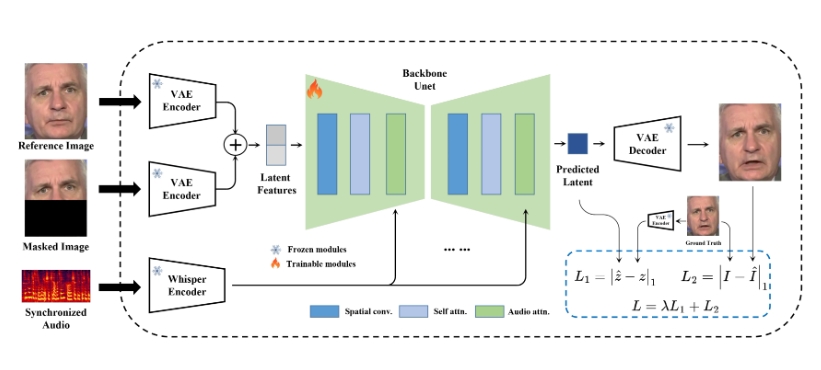
MuseTalk是一个高质量的实时音频驱动的唇部同步模型,能够依据输入的音频来修改未见过的面部图像,使面部动作与音频高度同步,以达到口型与声音匹配的效果。MuseTalk在256 x 256的面部区域上进行修改,支持多种语言的音频输入,如中文、英文和日语。该模型能够在NVIDIA Tesla V100上达到每秒30帧以上的实时推理速度,并支持调整面部区域中心点以显著影响生成结果。
MuseTalk能够在以下情景中被广泛使用:
-
视频配音与唇同步:在制作配音视频时,MuseTalk能够根据音频调整视频中人物的口型,使其与音频内容保持一致,提高视频的真实感和观看体验。
-
虚拟人视频生成:作为完整的虚拟人解决方案,MuseTalk配合MuseV(一个视频生成模型),可以用来创造与文本或图像内容对应的虚拟人视频,然后通过MuseTalk添加匹配的口型动画,创造出高度逼真的虚拟人演讲或表演视频。
-
视频制作与编辑:在视频制作和编辑过程中,当需要调整角色的台词或语言而不希望重新拍摄时,可以使用MuseTalk来调整角色的口型以匹配新的音频内容,进而节省时间和资源。
-
教育和培训:在教育领域,MuseTalk可以用来制作教学视频,通过虚拟人示范语言发音和口型,帮助学习者更好地掌握语言技能。
-
娱乐与社交媒体:内容创作者可以利用MuseTalk使照片或绘画作品“活”起来,创造有趣的口型同步视频分享到社交媒体平台,为粉丝提供新颖的互动体验。
MuseTalk提供了一个强大的工具,通过高质量的实时唇部同步技术,为视频制作、虚拟人生成、以及娱乐内容创作等多个领域带来便利与创新。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621