
OmniFusion
简单解释OmniFusion的功能
OmniFusion是一个高级的多模态人工智能模型,它通过整合传统语言处理系统无法直接处理的其他数据形式(如图像、音频、3D和视频内容)来扩展这些系统的功能。这意味着OmniFusion不仅能理解文字,还能理解和处理图片、可能的音频和视频等其他形式的信息。
为什么要使用OmniFusion?
在需要处理和理解多种不同类型数据的场景下,OmniFusion是极其有用的。想象一下,如果你有一些与图片相关的问题,或者你想要从一组图片中提取特定的信息,传统的语言模型可能就无能为力了。而OmniFusion就能派上用场,因为它不仅能理解文字问题,还能分析和解读图片中的内容。
OmniFusion的工作原理
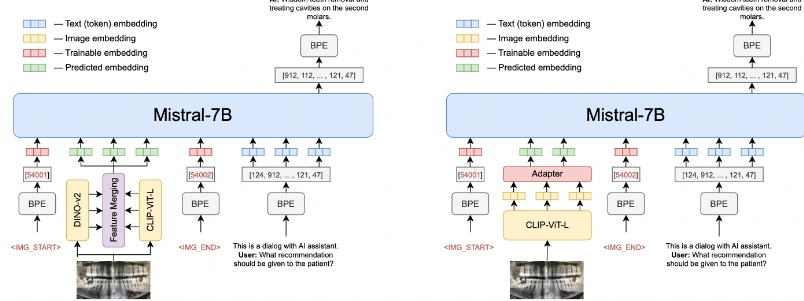
- 多模态整合: 它使用视觉编码器(如CLIP-ViT-L和Dino V2)来理解图片内容,并将这些视觉信息转化成能与文字信息一起处理的形式。
- 自适应学习: 通过一个特殊的“适配器”,OmniFusion能将视觉编码的内容映射到文本嵌入中,使得语言模型能够理解和使用这些信息。
- 训练过程: 开始时,先对适配器进行预训练,让它学会如何将图像映射到文本空间。然后,解冻语言模型以改善对对话格式和复杂查询的理解。
使用情景
- 图像字幕: 自动生成图片的描述文字。
- 问答系统: 在包括图片的情况下解答问题,比如根据图片内容回答问题。
- 文档和视觉问答: 分析文档图像或其他视觉资料以回答相关问题。
- 高级对话系统: 理解并回应涉及图像,甚至未来可能是音频或视频内容的对话。
OmniFusion的创新之处
- 多模态适配器: 一个高效的机制,可以将不同的数据形式(如视觉信息)转换成语言模型理解的格式。
- 定制的可学习令牌: 用于标记视觉数据在文本序列中的开始和结束,增强了模型处理多模态输入的能力。
- 较前期模型有所改进: 在多项基准测试中展现出优异的性能。
OmniFusion是处理和理解多种数据形式需求的强大工具。无论是在科研、开发新的应用程序,还是提升用户体验方面,OmniFusion都有着广泛的应用潜力,尤其在需要理解不仅仅是文字,还包括图片、音频和视频等多种信息的场合。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621