
LightLLM
LightLLM是一个基于Python的大型语言模型(LLM)推理和服务框架,以其轻量级设计、易于扩展和高速性能而著称。它聚合了多个广受好评的开源实现的优点,包括但不限于FasterTransformer、TGI、vLLM和FlashAttention等。
LightLLM的功能特点:
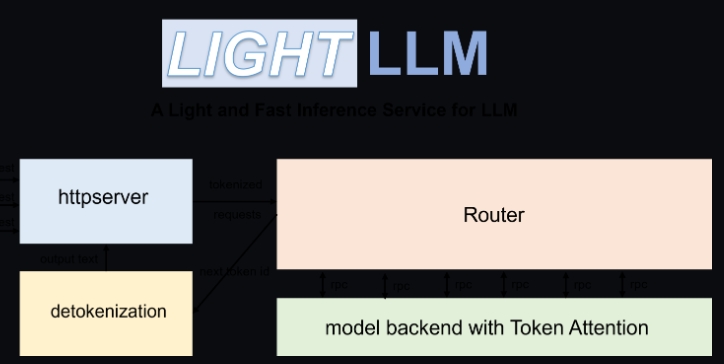
- 异步三过程协作:LightLLM将分词、模型推理和去标记操作异步执行,大幅度提升了GPU的利用率。
- 无填充操作(Nopad):支持多个模型的不填充注意力操作,有效处理不同长度请求。
- 动态批处理:能够动态调度请求的批次,提高处理效率。
- 引入FlashAttention:利用FlashAttention提高速度并减少GPU在推理过程中的内存占用。
- 张量并行:通过跨多个GPU的张量并行加速推理。
- Token Attention:实现了token-wise的KV缓存内存管理机制,在推理过程中实现零内存浪费。
- 高性能路由:与Token Attention结合,精细管理每个token的GPU内存,优化系统吞吐量。
- Int8KV缓存:这个功能将tokens的容量增加近两倍,目前仅llama支持。
在什么情况下使用LightLLM:
- 高速推理需求:当你需要在保持高性能的同时,对大型语言模型进行推理服务时。
- 资源限制环境:在资源有限(如GPU内存)但需要最大化资源利用效率的情景下。
- 支持多模型和多模态场景:如果你的项目需求不仅包括文本处理,还需要处理图像等多模式输入,LightLLM提供了对多模态模型的支持。
- 面对大量并发请求:当系统需要处理高并发请求且保持低延迟时,LightLLM的动态批处理和高效内存管理特性将非常有用。
支持的模型列表
LightLLM支持多种模型,包括BLOOM、LLaMA系列、StarCoder、Qwen-7b、ChatGLM2-6b、Baichuan系列、InternLM、Yi-34b、Qwen-VL、Llava等,以及特定的多模态模型如Qwen-VL、Qwen-VL-Chat和Llava系列,满足广泛的NLP处理需求。
快速启动和运行
LightLLM提供了详细的安装指南和Docker容器运行选项,使得部署变得简单快捷。无论是通过从源代码安装还是使用Docker容器,用户都可以方便地启动和运行服务。此外,LightLLM还支持静态推理性能测试,方便开发者调试和评估。
LightLLM的应用场景
LightLLM适用于需要高性能大型语言模型推理的场景,特别是当面对资源限制、多模态输入处理和高并发请求时,它的高效、灵活和易于扩展的特性将显著提升应用性能和用户体验。无论是研发人员在探索AI模型的潜力,还是企业在构建高效的NLP服务时,LightLLM都提供了一个可靠和强大的选择。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621