
Multi Modal Starter Kit
Multi Modal Starter Kit 概述 🤖📽️
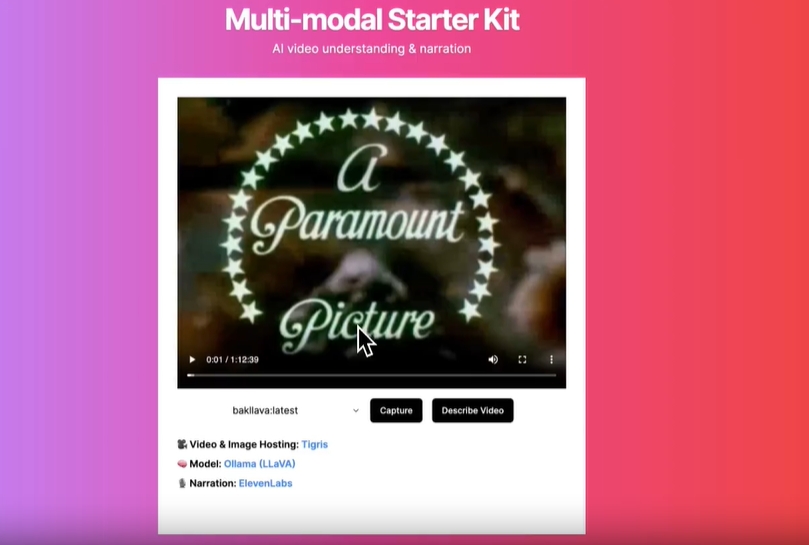
Multi Modal Starter Kit是一个多模态开发工具包,可以让AI为您选择的视频或场景进行旁白解说。它包括如何进行视频处理、帧提取以及如何最优地将帧发送到AI模型的示例。运行成本为0。
该工具包支持以下模型 👇🦙
- LLaVa(由Ollama提供支持)
- LLaVa-vicuna(由Ollama提供支持)
- BakLLaVA(由Ollama提供支持)
- …以及 https://ollama.com/library 上的许多其他模型
- GPT-4v
技术栈包括
- 💻 视频和图像托管:Tigris
- 🦙 推理:Ollama,也提供使用OpenAI的选项
- 🔌 GPU:Fly
- 💾 缓存:Upstash
- 🤔 AI响应发布/订阅:Upstash
- 📢 视频旁白:ElevenLabs
- 🗺️ 工作流程编排:Inngest
- 🖼️ 应用逻辑:Next.js
- 🖌️ 用户界面:Vercel v0
使用场景
Multi Modal Starter Kit适用于需要在视频内容中加入AI旁白、解说或其他形式的人工智能生成内容的场合。它对于开发者来说是一个零成本、全面的解决方案,无论是想进行模型对比、AI旁白生成还是其他视频和图像处理任务,都可以找到所需的工具和示例。
这个工具包特别适用于以下几种情况:
- 开发者希望在视频中加入由人工智能生成的旁白或评论。
- 在线教育平台需要通过AI整合大量的图像和视频内容,为其课程内容增添解说和分析。
- 媒体公司想要在其新闻报道或纪录片中使用AI来自动生成旁白,提高生产效率和内容的多样性。
- 在线营销和广告公司寻求创新方式通过AI旁白为其视频广告添加吸引力。
- 研究人员或学生在学术研究项目中,需要分析和处理视频数据,利用AI技术提取信息和生成描述性内容。
对于希望融合视频处理、人工智能、和声音旁白技术的开发者和内容创作者而言,Multi Modal Starter Kit提供了一个全面且成本效益高的解决方案。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621