
Reader
Reader是一个为语言模型(LLM)设计的工具,旨在改善这些模型处理网页内容时的输入质量。它通过简化的方式将任意URL的内容转换成更适合语言模型处理的格式。这种处理不仅包括提取主要内容,去除不必要的格式和杂质,还可能包括将内容分解为更容易由模型处理的形式。
使用情景
-
提升模型输出质量:当你希望提升你的语言模型或者RAG(Retrieval-Augmented Generation)系统针对特定网页内容的处理和理解能力时,可以使用Reader。通过标准化的输入格式,Reader帮助确保模型可以更准确地理解和响应给定的内容。
-
数据流式处理:在需要即时处理大量数据,或者希望在数据IO(输入/输出)和模型处理时间间进行交错以提高效率的情况下,Reader的流式模式提供了一个优越的解决方案。这种模式允许数据以流的形式被提供给模型,帮助减轻服务器负载,加快响应速度。
-
处理大型文档:当目标网页内容庞大、标准模式无法完全渲染时,流式模式也显示出其优势。Reader的这一模式可确保即便是大型文档也能高效地被分割并提供给语言模型处理。
-
初步的JSON化处理:虽然当前为初期阶段,Reader也支持将网页内容转换成简单的JSON格式,包含URL、标题和内容三个字段。这对于希望进一步处理或分析网页数据的开发者而言,提供了一种方便的入口。
如何使用
-
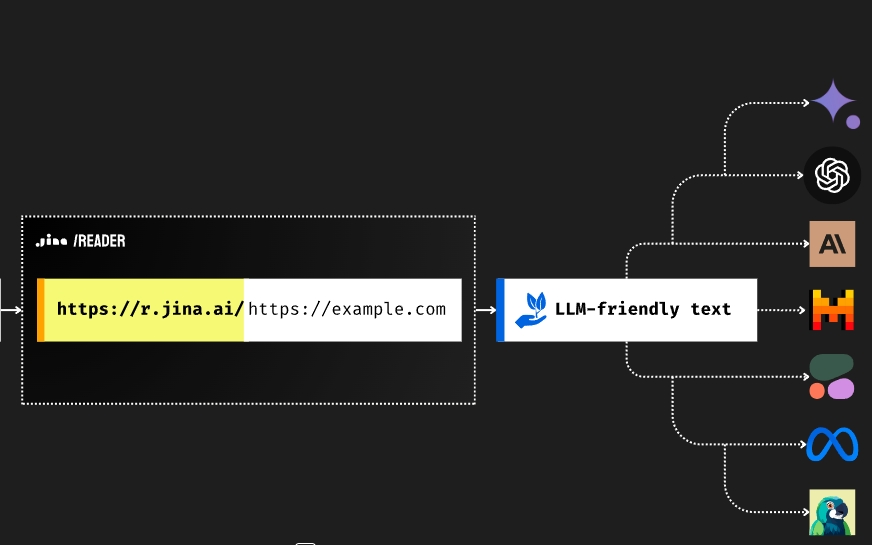
标准模式:直接将
https://r.jina.ai/前缀加到任何URL之前即可获取LLM友好的输入格式。 -
流式模式:通过适当的accept-header,可以控制内容以流的形式输出,适用于需要快速处理或大型内容的场景。
-
JSON模式:通过设置不同的accept-header,可以将内容转换为简单的JSON结构,方便进一步处理。
安装和运行
需要Node v18和Firebase CLI工具。克隆项目后,切到后端目录并安装依赖即可运行。
使用场合
- 开发者或数据科学家可以使用Reader来优化他们的语言模型输入,无论是进行学术研究、产品开发,还是单纯的内容探索。
- 在建立对外部内容有依赖的应用时,如自动摘要生成、内容推荐等场景,使用Reader可以提高处理质量和效率。
- 当需要从网页动态获取数据并以特定格式处理时,Reader的各种模式提供了灵活的选择。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621