
Automatic_Speech_Annotator
Automatic Speech Annotator是一种自动语音处理工具,它结合了多种技术来分析和转录会话英语语音数据。这个工具的主要功能包括语音活动检测、重叠语音检测、说话者分离(Speaker Diarization)以及自动语音识别。通过这一系列的处理步骤,Automatic Speech Annotator能够将复杂的语音数据转换成带有详细注释的文本格式,这对于许多领域的研究和应用都是非常有用的。
具体来说,Automatic Speech Annotator的处理流程如下:
- 语音活动检测(Voice Activity Detection, VAD):先通过一个语音活动检测模型移除所有非语音部分,如静默、音乐等,只保留语音信息。
- 重叠语音检测:由于多人同时说话会影响说话者分离和语音识别的效果,因此使用重叠语音检测模型来识别并处理重叠语音的部分。
- 说话者分离(Speaker Diarization):经过清理的数据输入到先进的说话者分离系统中,获取每个时间步的说话者信息,每个分割出来的音频段都会被标记上说话者的身份,例如Speaker_00。
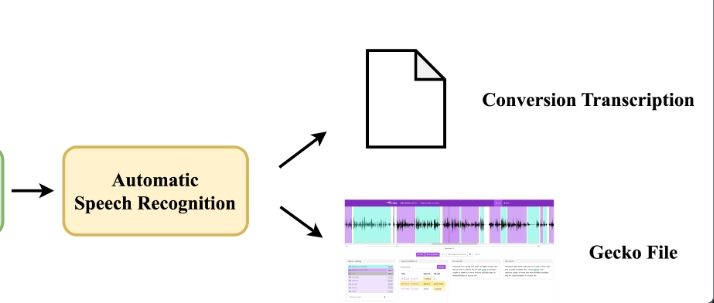
- 自动语音识别(Automatic Speech Recognition):使用中等大小的whisper模型将这些音频文件转录成文本。
使用场合
Automatic Speech Annotator特别适合在需要处理大量会话英语录音的场合,例如学术研究、会议记录、面试分析、语音数据集创建等。通过自动化的处理流程,它可以有效地从复杂的音频文件中提取出有用的信息,节省人工转录和标注的时间和成本。
此外,生成的文本注释可以用于多种应用,如自然语言处理、语音识别训练、情绪分析等。其中,提到的生成的文件还可以用于Gecko注释和GPT-4注释,这说明Automatic Speech Annotator不仅能够支持传统的语音处理任务,还能与最新的AI技术如GPT系列模型相结合,为研究和开发提供更多可能性。
当面对需要快速、准确处理和分析大量英语会话语音数据的任务时,使用Automatic Speech Annotator是一个非常合适的选择。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621