
FlashRAG
FlashRAG:一款高效的RAG研究Python工具包介绍
FlashRAG 是一个用于再现和开发检索增强生成(RAG)研究的Python工具包。该工具包包括32个预处理后的RAG基准数据集和12种最先进的RAG算法。
主要特性
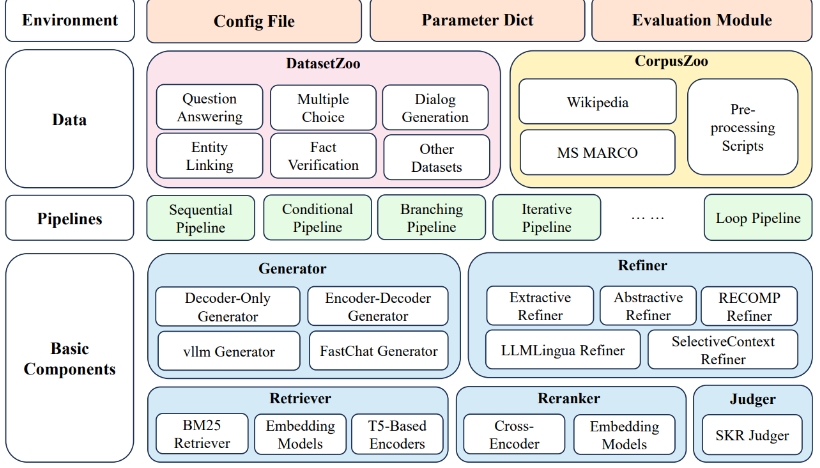
- 广泛且可定制的框架:包含RAG场景中所需的关键组件,如检索器、重排序器、生成器和压缩器,允许灵活地组装复杂的流水线。
- 全面的基准数据集:涵盖32个预处理后的RAG基准数据集,用于测试和验证RAG模型的性能。
- 预实现的高级RAG算法:基于此框架,提供了12种先进的RAG算法,并可以在不同设置下轻松复现结果。
- 高效的预处理阶段:提供各种脚本简化RAG工作流程的准备,如语料库处理、检索索引构建和文档预检索等。
- 优化的执行:通过工具如vLLM、FastChat和Faiss实现LLM推理加速和向量索引管理来提升库的效率。
安装
通过从GitHub克隆代码库并安装即可开始使用(需Python 3.9以上):
git clone https://github.com/RUC-NLPIR/FlashRAG.git
cd FlashRAG
pip install -e .
快速开始
可以通过运行以下代码使用提供的玩具数据集实现一个简单的RAG流水线:
cd examples/quick_start
python simple_pipeline.py \
--model_path=<LLAMA2-7B-Chat-PATH> \
--retriever_path=<E5-PATH>
此外,可以使用提供的流水线类来实现RAG流程。只需要配置config并加载相应的流水线即可。
使用场景
- 学术研究:研究者可以用它来复现现有的SOTA工作或实现自定义的RAG流程和组件。
- 工业应用:企业可以利用其模块化设计、预实现的算法和高效的执行能力来开发和优化自身的RAG应用。
- 教育与教学:适合作为RAG相关课程的工具包,帮助学生熟悉和理解检索增强生成的原理和实现方式。
通过FlashRAG,用户可以轻松复现当前最先进的RAG方法,也可以使用提供的组件自由组装和扩展RAG模型的工作流程,极大地方便了RAG研究的发展和应用。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621