
HippoRAG
HippoRAG 简介
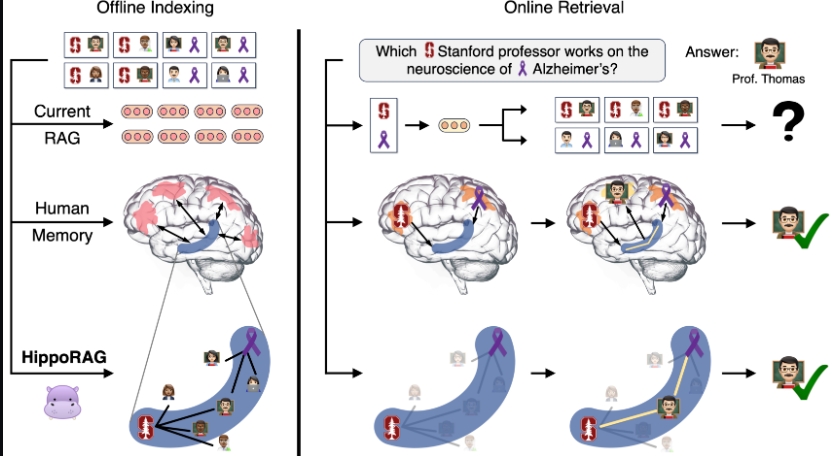
HippoRAG 是一种受人类长期记忆神经生物学启发的新颖的 “检索增强生成(Retrieval Augmented Generation, RAG)” 框架。它使得大型语言模型(Large Language Models, LLMs)能够持续地从外部文档中整合知识。实验表明,HippoRAG 可以为 RAG 系统提供通常需要复杂且高延迟的迭代 LLM 管道才能实现的功能,但其计算成本仅为后者的一小部分。
HippoRAG 的使用场景
HippoRAG 主要应用于以下场景:
- 学术研究:用来整合来自不同文档和来源的知识,辅助科研人员进行文献回顾和信息整合。
- 企业知识库:帮助企业建立复杂的知识管理系统,将内部文档和外部资源中的信息整合起来,以支持各种业务决策。
- 问答系统:增强问答系统的回答质量,使其能够从更广泛的文档中检索并生成高质量的答案。
- 客户支持:为客户支持系统提供一个智能检索和回答机制,提高响应速度和准确性。
HippoRAG 的使用步骤
-
环境设置:
- 创建并激活一个 conda 环境:
conda create -n hipporag python=3.9 conda activate hipporag pip install -r requirements.txt- 配置 GPU 设备和 API 密钥:
export OPENAI_API_KEY='你的 OpenAI API 密钥' export TOGETHER_API_KEY='你的 TogetherAI API 密钥' -
设置数据:
- 创建检索语料库,遵循
data/sample_corpus.json的格式。 - 可选地创建查询 JSON 文件,遵循
data/sample.json的格式。
- 创建检索语料库,遵循
-
索引数据:
- 使用 ColBERTv2 进行同义词边索引:
bash src/setup_hipporag_colbert.sh $DATA $LLM $GPUS $SYNONYM_THRESH $LLM_API- 使用 HuggingFace 检索编码器进行同义词边索引:
bash src/setup_hipporag.sh $DATA $HF_RETRIEVER $LLM $GPUS $SYNONYM_THRESH $LLM_API -
检索操作:
- 对预定义查询集进行检索:
python3 src/ircot_hipporag.py --dataset $DATA --retriever $RETRIEVER --llm $LLM_API --llm_model $LLM --max_steps 1 --doc_ensemble f --top_k 10 --sim_threshold $SYNONYM_THRESH --damping 0.5- 直接与 HippoRAG API 集成:
from hipporag import HippoRAG hipporag = HippoRAG("sample_dataset", "gpt-3.5-turbo-1106", "facebook/contriever", doc_ensemble=True) queries = ["Which Stanford University professor works on Alzheimer's"] for query in queries: ranks, scores, logs = hipporag.rank_docs(query, top_k=10) print(ranks) print(scores)

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621