
PAI-RAG
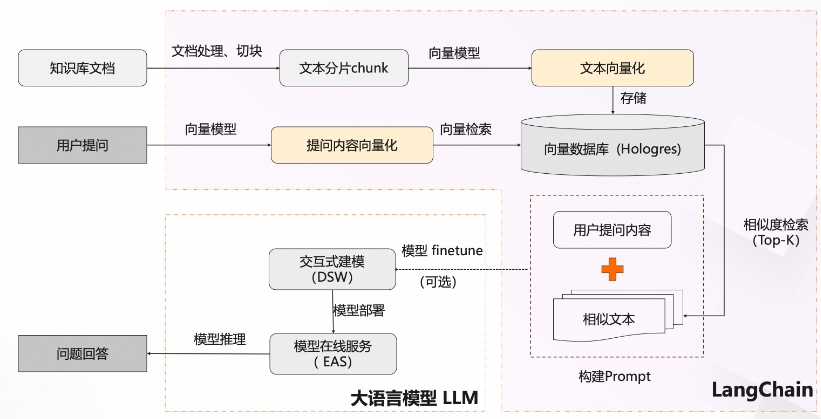
PAI-RAG是一个基于大语言模型和多向量数据库的知识库问答系统,它的主要功能和应用场景可以总结如下:
功能概述
- 支持多种向量数据库:包括Hologres、Elasticsearch、OpenSearch、AnalyticDB、以及本地FAISS向量库。
- 支持多种向量化模型:包括中文、英文和多语言模型,如SGPT、text2vec、paraphrase-multilingual和OpenAIEmbeddings等。
- 大模型服务:支持通过PAI-EAS部署的大模型服务,如Qwen、chatglm、llama2、baichuan等,同时也支持调用ChatGPT(需提供OpenAI Key)。
- 知识库构建:
- 文档处理与切片:将文档分成不同格式和长度的文本块。
- 向量化:将文本块转化为向量并导入向量数据库。
- 用户查询:用户的查询也会被向量化,并通过向量相似度检索获取最相关的文本块(Top-K)。
- 构建Prompt:将用户查询和相关文本块整合起来,形成Prompt(提示)。
- 大模型推理:利用大模型生成回答,必要时可以对模型进行微调。
应用场景
PAI-RAG通常在以下场景下使用:
- 企业内部知识库问答:公司内部文档多样且复杂,通过该系统可以快速检索文档并回答员工问题,提升工作效率。
- 客户支持和服务:应用于客服系统,利用现有的文档资料回答客户问题,提高响应速度和准确性。
- 教育和培训:用于提供课程内容检索和解答学生问题,帮助学生更好地理解课程内容。
- 技术支持:用于技术文档和开发文档的检索和问答,支持技术人员快速找到所需信息。
白盒化自建方案与一体化方案对比
PAI-RAG的白盒化方案与一体化方案相比,主要优势在于灵活性和可定制性:
| 维度 | 白盒化自建 | 一体化方案 |
|---|---|---|
| 模型灵活度 | 支持多种中英文开源模型,也支持API调用 | 仅支持内嵌大模型 |
| 模型推理加速 | 支持vLLM、flash-attention等加速框架 | 一般不支持 |
| 向量数据库 | 支持多种向量数据库 | 仅支持内置 |
| 业务数据微调 | 支持 | 一般不支持 |
| 向量化模型 | 支持多种向量化模型和不同维度 | 主要内置,有限 |
| 超参数调整 | 支持多种超参数如文档召回和模型推理参数 | 有的仅支持temperature和topK |
| Prompt模板 | 提供多种Prompt模板并支持用户自定义 | 不支持 |
| 知识库文件格式及上传 | 支持多种文件格式和批量上传 | 仅支持一定文件格式和单个上传 |
| 文本处理 | 可自定义文档切块方式 | 基于模型,不能调整 |
开发与部署流程
开发环境
-
方案一:本地conda安装
- 创建虚拟环境并安装依赖。
- 下载RefGPT模型以供后续操作。
-
方案二:Docker启动
- 拉取Docker镜像。
- 启动Docker容器。
- 挂载本地目录并下载RefGPT模型。
启动WebUI
通过以下命令启动WebUI:
uvicorn webui:app --host 0.0.0.0 --port 8000
页面配置
- Embedding Model:配置向量化模型及对应的向量维度。
- LLM:配置大模型服务的URL和token。
- Vector Store:配置向量数据库。
知识库上传和处理
- 支持多文件格式和批量上传。
- 配置文本处理参数,如块大小(chunk size)和重叠大小(overlap size)。
聊天问答
- 支持不同问答方式:检索、LLM、RAG。
- 支持模型推理参数调优和多种Prompt模板。
- 支持上下文对话和对话总结。
PAI-RAG提供了一个灵活而强大的框架,用于构建基于大语言模型的知识库问答系统,适用于各种复杂的知识管理和问答需求。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621