
VILA
VILA是一种视觉语言模型(Visual Language Model,简称VLM),它通过大规模交错的图像-文本数据进行预训练,从而能够实现视频理解和多图像理解的能力。它特别适合于视频内容的分析、多图像间关系的推理,以及图像和文本信息的融合处理。
以下是VILA的功能和使用场景的简单总结:
主要功能
- 视频理解:VILA能够分析视频内容,理解视频中的场景、动作和事件等。
- 多图像理解:VILA可以处理和分析多个图像之间的关系,例如推理出图像序列中的故事线。
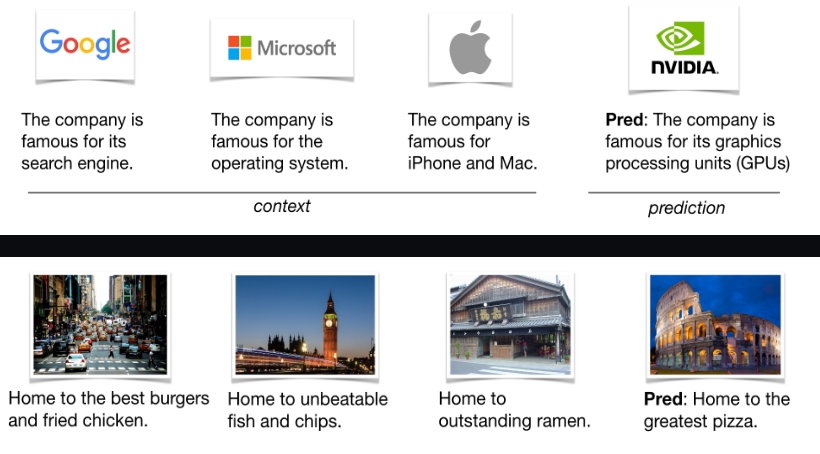
- 视觉链式思考(Visual Chain-of-Thought):VILA能够像人类思考一样,通过一系列视觉信息点来推理和解决问题。
- 更好的世界知识理解:经由在大量图像-文本数据上的预训练,VILA对于世界的理解更加深刻。
使用场景
- 内容创作和媒体产业:对于需要大量分析视频或图像内容的行业,比如新闻、娱乐和社交媒体,VILA可以自动化解析和描述视频内容,提高内容创作的效率。
- 教育和培训:VILA可以用于制作互动教学材料,通过视频理解和多图像理解来帮助学生更好地学习和理解复杂的概念。
- 安全监控:在安全监控领域,VILA能够对监控视频进行实时分析,识别和预警潜在的安全风险。
- 医学影像分析:利用其强大的图像理解能力,VILA可以辅助医生分析医学影像,提高疾病诊断的准确率。
技术亮点
- VILA通过交错的图像-文本预训练,充分利用了视觉和语言信息之间的互补性,提高了模型对于复杂视觉场景的理解能力。
- VILA模型经过AWQ(Adaptive Weight Quantization,自适应权重量化)的4位量化处理后,可以在边缘设备上高效部署,有助于实现实时的视频和图像分析。
- VILA开源包括训练代码、评估代码、数据集和模型检查点,便于研究人员和开发者学习和应用。
总的来说,VILA是一款强大的视觉语言模型,它通过预训练实现了对视频和多图像内容的高效理解。它的应用场景广泛,特别适合视频内容分析、互动教学、安全监控和医学影像分析等领域。通过AWQ技术的支持,VILA还可以在各种设备上高效运行,为实时图像和视频处理提供了可能。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621