
llama3v
llama3v是一种由Llama3 8B和siglip-so400m驱动的SOTA视觉模型。该模型可以通过GitHub和Huggingface获取模型权重和相关代码。其主要特点包括:
- 开源的最先进视觉语言模型(VLLM)
- 可以在本地快速推理
- 可通过Huggingface获得模型权重
- 已发布推理代码(训练代码将很快发布)
使用场景
llama3v可以在多种场景中使用,包括但不限于:
- 图像分类:根据输入图像生成对应的类别标签。
- 图像描述生成:输入图像后,模型生成对图像内容的自然语言描述。
- 多模态问答系统:用户输入一张图像和一个文本问题,模型根据图像内容生成相应答案。
- 视觉内容检索:通过自然语言描述查询相关图像。
示例代码
以下是如何使用Transformers库调用llama3v的示例:
from transformers import AutoTokenizer, AutoModel
from PIL import Image
model = AutoModel.from_pretrained("mustafaaljadery/llama3v").cuda()
tokenizer = AutoTokenizer.from_pretrained("mustafaaljadery/llama3v")
image = Image.open("test_image.png")
answer = model.generate(image=image, message="What is this image?", temperature=0.1, tokenizer=tokenizer)
print(answer)
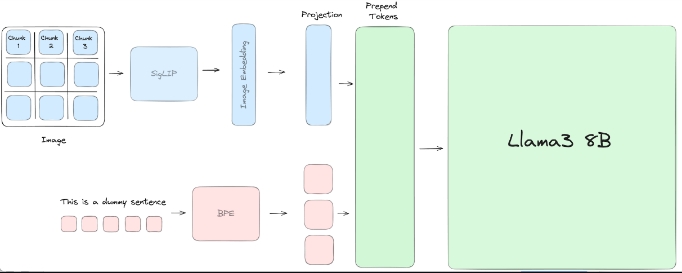
模型首先通过视觉模型提取图像特征,然后通过语言模型生成答案。
训练过程
在训练过程中,llama3v结合了siglip-so400m模型用于视觉处理,与Llama3 8B模型用于多模态(图像-文本)的输入和文本生成。首先在大约60万张图像上进行预训练,仅调整投影层的权重,然后在大约100万张图像上进行微调,微调过程中冻结siglip-so400m模型和投影层的权重,仅调整Llama3 8B模型的权重。
更多关于我们的训练过程,请参见这里。
致谢
该项目的开发感谢以下人员的贡献:

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621