
Finetuning Whisper
Finetuning Whisper的功能目的是为了提高模型对于不同音频长度(动态音频环境)的健壮性,通过调整audio_ctx参数来实现这一点。在传统情况下,Whisper模型在处理音频时需要将音频长度固定为30秒,这就意味着即使是只有短短几秒的音频,也需要添加大量的静音来填满这30秒,导致编码器(encoder)不得不浪费在静音上的处理时间。这在资源有限的设备上(比如手机)会增加显著的延迟,尤其是在实时语音输入这样的应用场景下。
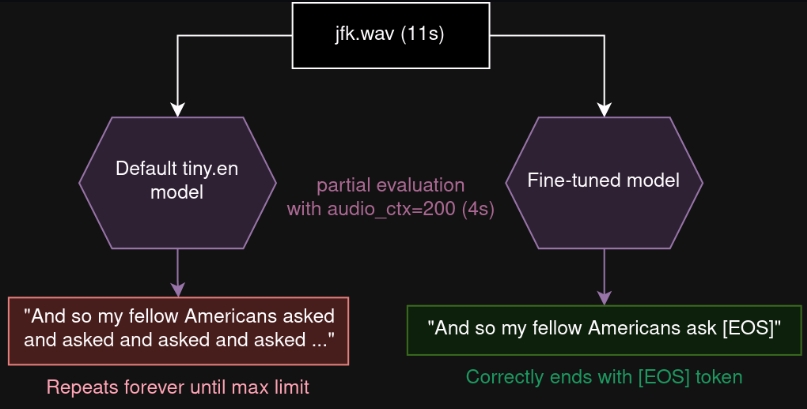
为了解决这个问题,Whisper.cpp引入了audio_ctx参数,允许根据音频的实际长度动态调整,但是这个调整如果太过随意,可能会让模型表现出异常,比如重复输出文本。
为了使模型能够更好地处理动态音频环境,提出了一种Finetuning(微调)方法。这种方法通过对比原始模型和目标模型(调整了audio_ctx参数的模型)的隐藏状态,并利用L2 loss来调整目标模型,使其能够在动态音频环境中更加稳定地工作,而不是出现重复或错误太多的情形。
实验结果显示,微调后的模型在使用动态音频环境时的词错误率(Word Error Rate, WER)较未微调的模型显著降低,并且接近于在标准音频环境中的表现,同时保持了对其他语言的支持并没有明显下降,表明微调成功地保留了模型的知识。
微调Whisper的功能特别适用于需要处理不同长度音频的场景,比如实时语音识别、语音输入等场合,尤其是在资源有限的设备上,可以显著减少延迟,提升用户体验。它通过对模型进行微调,让模型能够更灵活地处理各种长度的音频,而不是仅限于固定的30秒音频,这样就大大提高了模型的实用性和灵活性。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621