
AnimateDiff
AnimateDiff简介
AnimateDiff是一个能够将大多数社区模型转变为动画生成器的模块,无需额外的训练。由Yuwei Guo、Ceyuan Yang、Anyi Rao、Zhengyang Liang、Yaohui Wang、Yu Qiao、Maneesh Agrawala、Dahua Lin和Bo Dai开发,并在2024年的ICLR会议上获得了“Spotlight”奖项。
目前,AnimateDiff提供了四个版本:适用于Stable Diffusion V1.5的v1、v2和v3,以及适用于Stable Diffusion XL的sdxl-beta。最新版本包括SparseCtrl,允许通过多个条件图来控制生成过程。
使用场景
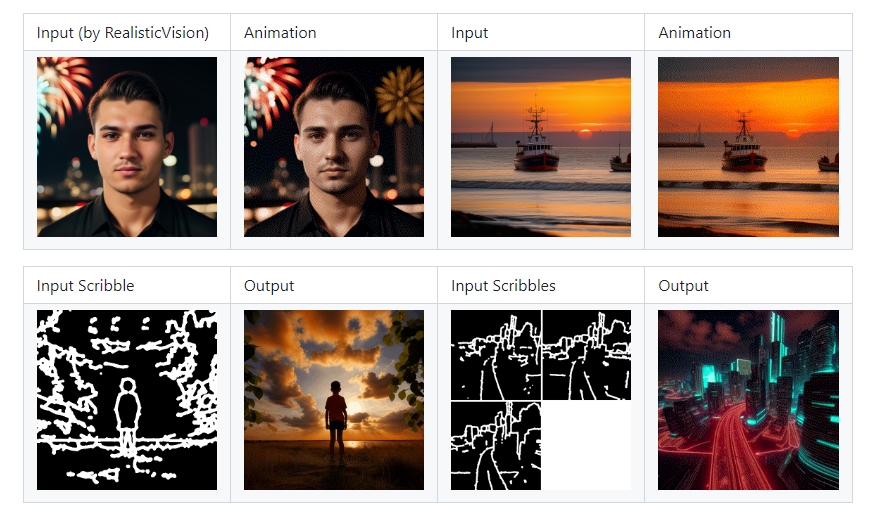
AnimateDiff的应用范围广泛,包括但不限于以下场景:
- 文本到视频生成:通过解析文本描述并生成相应的动画视频。
- 图像动画:将现有图像进行动画化,生成动态效果。
- 手绘草图到动画:利用手绘草图作为输入,生成相应的动态视频。
- 视频风格转换:将特定风格的视频转换为动画效果,如实现各种相机运动控制(缩放、平移、旋转等)。
- 高分辨率视频生成:支持生成高分辨率和多帧的视频内容,适用于不同的个性化模型。
- 领域适配与视觉属性调整:通过设置领域适配器,调整推理过程中视觉属性,例如去除水印等。
技术实现
AnimateDiff通过与Stable Diffusion模型的结合,实现了一键式动画生成。无需针对特定任务进行模型调优,系统就能高效地将静态图像或文本转化为动态视频。最近版本v3引入了Domain Adapter和SparseCtrl,进一步提升了模型在推断时的灵活性和控制力。
总结
AnimateDiff提供了一种无需繁琐训练即可轻松生成动画的方法,大大简化了动画制作流程,适用于多种文本到视频、图像动画及风格转换的场景。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621