
Audio-Mamba
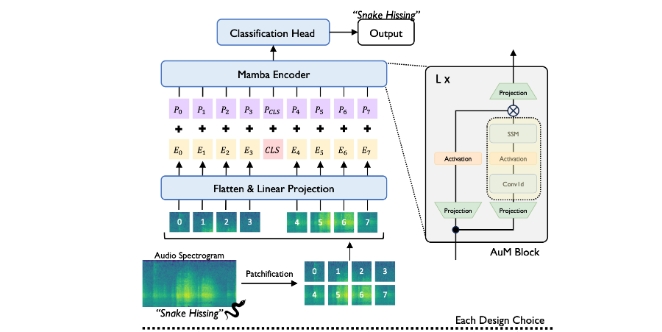
Audio-Mamba(AuM)是一种用于音频表示学习的双向状态空间模型,旨在进行音频分类。它是一种通用的、无自注意力机制的纯状态空间模型,实现了在各种音频分类基准上的训练和评估。Audio-Mamba基于AST和ViM的研究成果,并利用了Hugging Face的Accelerate库来支持高效的多GPU训练。
使用场景
Audio-Mamba主要应用于以下音频分类任务:
- Audioset:用来处理和分类大规模的一般音频数据集。
- AS-20K:处理和分类较小规模的音频数据。
- VGGSound:用于多类别音频识别。
- VoxCeleb:用于语音识别和验证。
- Speech Commands V2:识别特定的语音命令。
- EPIC-SOUNDS:用于复杂音频环境下的声音分类。
功能和特点
- 提供了从零开始训练和评估模型的必要代码。
- 支持多GPU高效训练。
- 提供了预训练的模型检查点,便于快速复现和进一步训练。
设置步骤
- 创建Conda环境:
conda create -n aum python=3.10.13 conda activate aum - 设置CUDA和CuDNN:
conda install nvidia/label/cuda-11.8.0::cuda-nvcc conda install nvidia/label/cuda-11.8.0::cuda conda install -c conda-forge cudnn - 安装PyTorch和其他依赖:
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118 pip install -r requirements.txt - 安装Mamba相关包:
pip install causal_conv1d==1.1.3.post1 mamba_ssm==1.1.3.post1 - 启用双向SSM处理:
cp -rf vim-mamba_ssm/mamba_ssm $CONDA_PREFIX/lib/python3.10/site-packages
推理与训练
提供了测试音频文件的推理示例脚本,以及每个数据集的评估和训练脚本。训练脚本参数可根据需要调整,支持多GPU训练配置。
预训练模型
预训练模型的检查点包含多种配置和数据集的详细性能指标,便于快速应用和调整。
通过上述描述,可以快速上手和运行Audio-Mamba,进行各种音频分类任务的研究和应用。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621