
GPTCache
GPTCache 简介
GPTCache 是一个用于构建大语言模型(LLMs)查询的语义缓存库。主要目的是通过缓存LLM的响应来降低API调用的成本并提高响应速度。
主要功能
- 成本降低:缓存查询结果,减少发往LLM服务的请求数量和Token数量,从而节省费用。
- 性能提升:缓存类似或相同的查询结果,提高响应速度,减少与LLM服务的交互时间。
- 可扩展性和可用性:缓存可以应对高并发,避免超过API速率限制,提高系统的可扩展性和可靠性。
- 开发与测试环境:提供接口以模拟LLM API,便于开发者在不连接LLM服务的情况下进行应用开发和测试。
工作原理
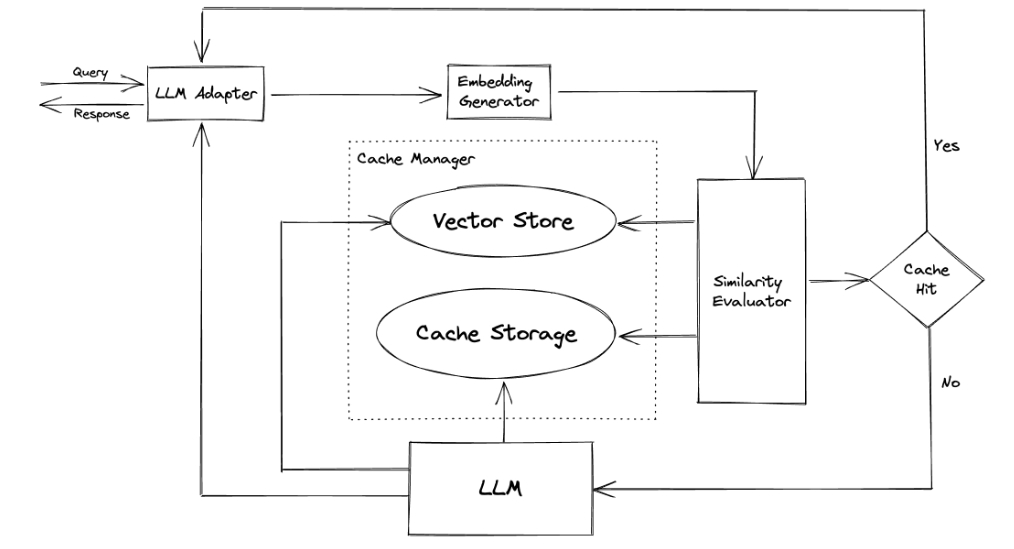
GPTCache 利用嵌入算法将查询转换成嵌入向量,并使用矢量存储进行相似度搜索。与传统的精确匹配缓存系统不同,GPTCache 采用语义缓存策略,存储并识别相似或关联的查询,提高缓存命中率。
模块设计
GPTCache 的模块化设计允许用户自定义语义缓存系统,包括以下模块:
- LLM适配器:整合不同LLM模型并统一其API和请求协议,目前支持OpenAI的ChatGPT等。
- 多模态适配器(实验性):整合跨领域大模型(如图像生成、音频转录),支持OpenAI的图像和音频API等。
- 嵌入生成器:从请求中提取嵌入用于相似度搜索,支持多种嵌入API,如OpenAI、ONNX、Hugging Face等。
- 缓存存储:存储LLM的响应,目前支持SQLite,并提供扩展接口,支持PostgreSQL、Redis等。
- 矢量存储:帮助找到最相似的请求,支持Milvus、FAISS、Chroma等矢量数据库。
- 缓存管理:控制缓存存储和矢量存储的操作,支持多种驱逐策略,如LRU、FIFO、LFU等。
- 相似度评估:基于不同策略评估输入请求与缓存中的请求相似度,决定是否匹配缓存。
使用指南
####### 快速安装
pip install gptcache
####### 基本示例
from gptcache import cache
from gptcache.adapter import openai
cache.init()
cache.set_openai_key()
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[{'role': 'user', 'content': 'what’s chatgpt'}]
)
print(response)
更多详细用法和示例可以参考官方的使用文档。
GPTCache 是一个开源项目,欢迎开发者贡献新功能、提升基础设施或者改进文档。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621