
Build a Large Language Model (From Scratch)
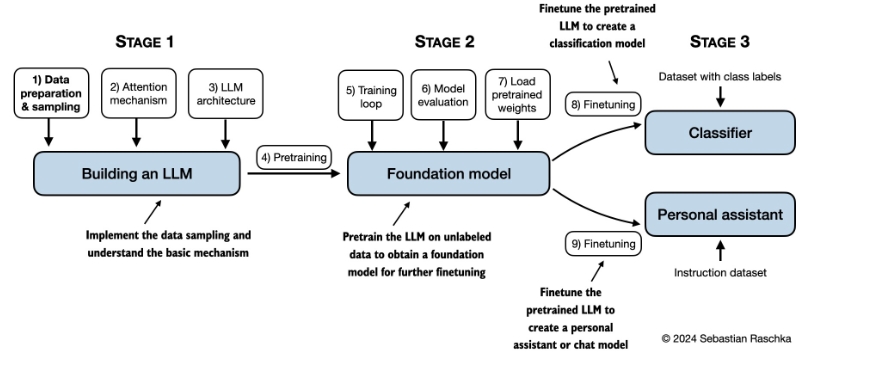
《从零开始构建大语言模型》(Build a Large Language Model From Scratch) 是一本通过逐步编码的方式,帮助读者理解并自己构建大型语言模型(LLM)的书籍。本书重点介绍了GPT类语言模型的编码、预训练和微调过程。作者Sebastian Raschka在书中通过清晰的文字、图表和示例,详细讲解了构建自有LLM的每个阶段,为读者提供了一个全方位的学习体验。
主要内容概述
- 理解大语言模型:介绍了LLM的基本概念和理论。
- 处理文本数据:涵盖了如何处理和准备训练数据。
- 编码注意力机制:详细讲解了注意力机制的实现方法。
- 从零开始实现GPT模型:带领读者一步步编写一个GPT模型。
- 无标签数据预训练:说明如何使用无标签数据对模型进行预训练。
- 文本分类微调:示范如何微调模型以进行文本分类任务。
- 指令跟随微调:讲解如何微调模型以使其更好地理解和执行指令。
使用场景
- 教育与学习:针对研究人员和学生,帮助他们深入理解LLM的内部工作机制。
- 研究与实验:为学术研究和实验提供一个从零开始的框架,可以用于探索和改进LLM。
- 快速原型开发:开发者可以使用该书和代码作为基础,快速生成定制化的LLM原型。
- 个人项目与应用:个人或小团队可以基于书中提供的指南,开发自己的语言应用,如聊天机器人、文本生成工具等。
硬件要求
书中主要章节的代码设计旨在使其能够在普通笔记本电脑上运行,不需要专门的硬件。这种设计确保了广泛的受众可以参与学习和实践。此外,如果有GPU设备,代码也能自动利用其进行加速计算。
额外材料
书中还提供了许多附加材料,包括如何进行Python环境设置、关于Byte Pair Encoding的比较、不同多头注意力机制实现的比较等。这些材料为对特定主题感兴趣的读者提供了进一步的学习资源。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621