
MG-LLaVA
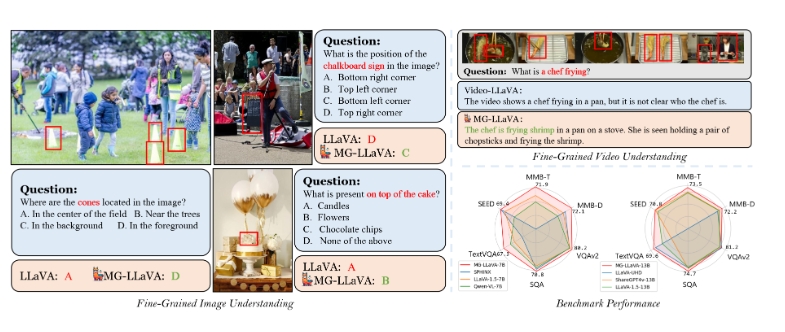
MG-LLaVA是一种创新的多任务视觉语言模型(MLLM),通过集成多层次的视觉处理流,增强了模型的视觉处理能力。这些视觉处理流包括低分辨率、高分辨率和基于对象的特征。MG-LLaVA引入了一个额外的高分辨率视觉编码器,以捕捉细粒度的视觉细节,并通过一个卷积门融合网络将这些细节与基本视觉特征融合。此外,MG-LLaVA还整合了由离线检测器识别的边界框所派生的对象级特征,通过这些调整提高了模型的对象识别能力。
MG-LLaVA在公开的多模态数据集上进行了指令调优训练,并展示了出色的感知能力。
MG-LLaVA的使用场景
- 视觉问答:MG-LLaVA可用于根据输入图像和文本问题,给出准确的答案。
- 图像描述生成:模型可以对输入的图像生成详细的文字描述,适用于内容生成和盲人辅助工具。
- 对象检测与识别:通过高精度的对象识别能力,MG-LLaVA可以在人群监控、自动驾驶和工业检测中应用。
- 多模态内容检索:支持通过文本查询搜索相关图片,以及通过图片查找对应的文本描述,有助于内容管理和信息检索。
- 增强现实:在增强现实应用中,MG-LLaVA可以为用户理解和互动提供实时的视觉和语义信息。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621