
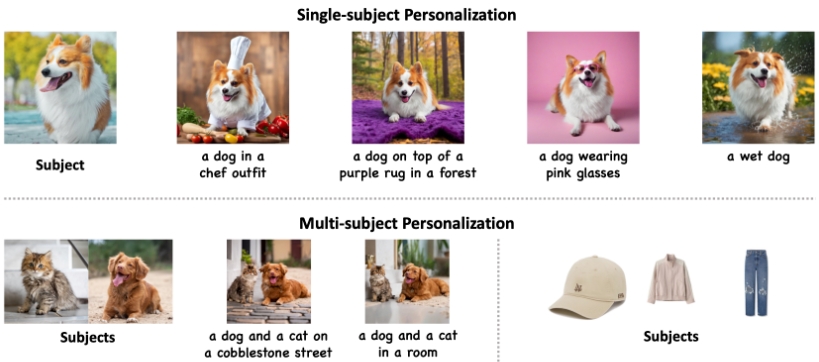
MS-Diffusion
MS-Diffusion是一个多主体零样本图像个性化生成框架,采用布局指导技术,解决了在多主体图像生成领域中的主要挑战。该框架通过引入基础采样器和多主体交叉注意机制,确保在生成图像时每个主体的细节和位置得到准确保留,并实现各主体间的协调组成。
使用场景
MS-Diffusion可以广泛应用于以下场景:
- 多主体图像生成:生成包含多个特定主体的图像,同时保持各主体的细节和布局,例如家庭照片、团体肖像等。
- 图像个性化:根据文本描述生成个性化的图像,例如根据客户描述生成定制化的商品广告图像。
- 艺术创作:帮助艺术家快速生成符合特定布局和内容描述的艺术作品。
- 广告和市场营销:通过生成包含多个品牌元素的广告图,提高广告的个性化和多样性。
技术细节
- 基础采样器:负责从输入文本中提取视觉信息,将其与特定的实体和空间约束相关联。
- 多主体交叉注意机制:在多主体注意层中实现图像条件与扩散潜变量的精确交互,保证每个主体条件作用于特定的图像区域。
模型下载和使用
- 从预训练模型(如SDXL-base-1.0和CLIP-G)获取基模型。
- 下载MS-Diffusion的检查点。
- 使用
inference.py脚本进行推理,可以根据需要调整输入参数和scale参数。
新功能
- 自动布局指导:利用文本交叉注意图作为伪布局指导,适应复杂的主体布局场景。
- 多主体缩放:支持为不同的主体设置不同的缩放比例,以提高图像生成的灵活性。
基准测试
提供了一个名为MS-Bench的测试基准,包含多种数据类型和组合类型,用于综合评估模型性能。
通过上述功能和技术,MS-Diffusion在图像和文本的保真度方面超越了现有模型,推动了个性化文本到图像生成的发展。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621