
OpenVLA
OpenVLA是一个开放源代码的视觉-语言-行动(VLA)模型,具有7B参数。它是基于从Open X-Embodiment数据集中预训练的970,000个机器人操作实例构建的。OpenVLA在泛化机器人操纵策略方面达到了新的最先进水平,能够开箱即用地控制多种机器人,并通过高效的参数调整适应新的机器人设置。
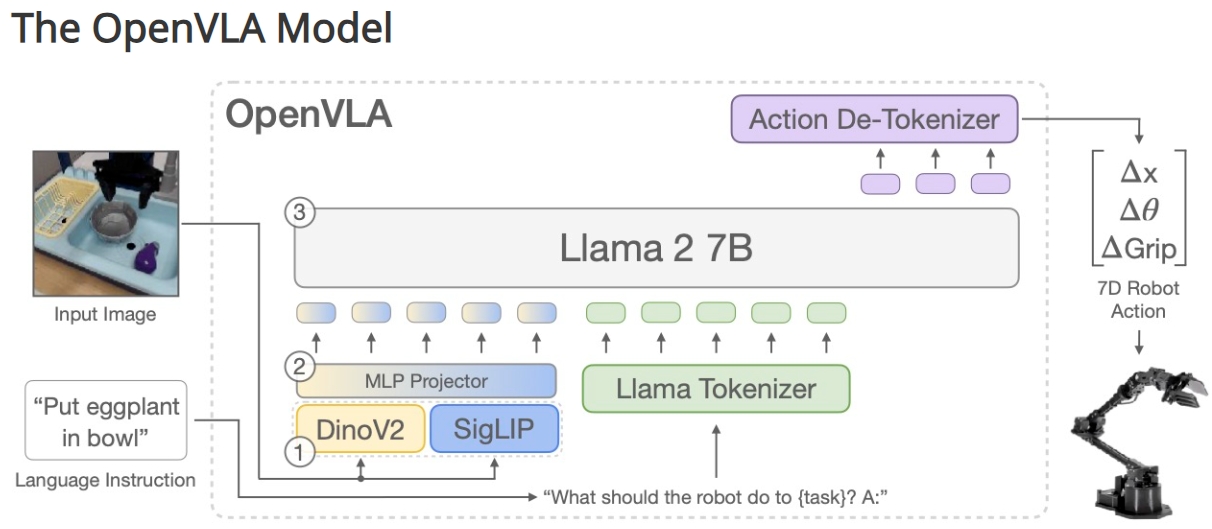
模型结构
OpenVLA主要由三个部分组成:
- 融合视觉编码器:包括一个SigLIP与DinoV2骨干网络,负责将图像输入映射为“图像补丁嵌入”。
- 投影器:将视觉编码器的输出嵌入映射到大语言模型的输入空间。
- Llama 2 7B语言模型骨干:生成经过标记的输出动作,这些动作可以直接在机器人上执行。
训练数据
模型通过Open X-Embodiment数据集中970,000个机器人操作轨迹进行训练。训练在64个A100 GPU上持续15天。
实验与评估
OpenVLA在多种机器人平台上展示了出色的性能,包括WidowX和Google Robot平台,并在一般化任务,如视觉、运动、物理和语义一般化任务中表现优异。它在某些复杂的语义一般化任务中略逊于RT-2-X(一个闭源的55B参数模型)。
数据高效的适应能力
OpenVLA在新任务和机器人设置中表现出色,特别是在涉及多任务、多对象场景的任务中,显示出优于现有最先进的模型Octo和Diffusion Policy的良好性能。它在所有测试的任务中至少能达到50%的成功率。
参数高效微调
针对参数高效微调,LoRA方法在性能和训练内存消耗方面达到了最佳的平衡,仅微调1.4%的参数即可达到完全微调的性能。
开源资源
OpenVLA的检查点和PyTorch训练管道是完全开源的,模型可以从HuggingFace下载和微调。
贡献与合作
研究由斯坦福大学、UC伯克利、丰田研究所、Google DeepMind等多个机构合作完成。多个作者平等贡献。
通过以上特性,OpenVLA为机器人视觉、语言与行动的集成提供了强大的解决方案,并且可以适应多种复杂环境和任务需求。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621