
StreamSpeech
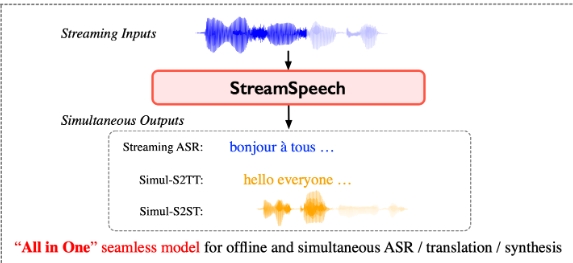
StreamSpeech 是一种最新的同时语音到语音翻译(Simultaneous Speech-to-Speech Translation, S2ST)技术,基于多任务学习实现。它在离线和同步语音到语音翻译上均达到了最先进的性能。StreamSpeech 通过一个无缝的多任务模型实现了流式语音识别(Streaming ASR)、同步语音到文本翻译(Simultaneous Speech-to-Text Translation, S2TT)和同步语音到语音翻译(Simultaneous Speech-to-Speech Translation, S2ST),并能够在同步翻译过程中展示中间结果,如语音识别或翻译结果,从而提供更全面低延迟的通信体验。
使用场景
- 同时语音到语音翻译(Simultaneous S2ST):适用于国际会议、实时翻译服务等需要实时语音翻译的场景。
- 同时语音到文本翻译(Simultaneous S2TT):适用于需要语音转录并翻译成目标语言文本的应用,如会议纪要、新闻字幕等。
- 流式语音识别(Streaming ASR):可用于实时语音转写,如实时会议记录、语音助手等。
模型优势
- 最先进的性能:在离线和同步语音到语音翻译任务上表现优异。
- 多任务学习:一个模型实现多种任务,简化了系统设计。
- 低延迟高质量:在提供高准确度的同时,确保低延迟,提升用户体验。
快速开始
- 模型下载:提供多种语言的预训练模型,如法语-英语、西班牙语-英语、德语-英语等。
- 数据和配置准备:根据提供的示例准备测试数据和配置文件。
- 使用SimulEval评估:通过SimulEval进行流式ASR、同步S2TT和同步S2ST的推断和评价。
StreamSpeech 提供丰富的训练和评估脚本,便于用户训练自己的模型并进行离线和同步评估。项目主页提供了示例音频,用户可以通过这里聆听StreamSpeech的翻译效果。
引用方式
如果您觉得我们的工作对您有帮助,请引用我们的论文:
@inproceedings{streamspeech,
title={StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning},
author={Shaolei Zhang and Qingkai Fang and Shoutao Guo and Zhengrui Ma and Min Zhang and Yang Feng},
year={2024},
booktitle = {Proceedings of the 62th Annual Meeting of the Association for Computational Linguistics (Long Papers)},
publisher = {Association for Computational Linguistics}
}
通过这种方法,StreamSpeech 可以极大地提升跨语言交流的效率和质量,为各种实时语音翻译应用提供强大的技术支持。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621