
VoCo-LLaMA
VoCo-LLaMA: 使用大型语言模型进行视觉压缩
简介:
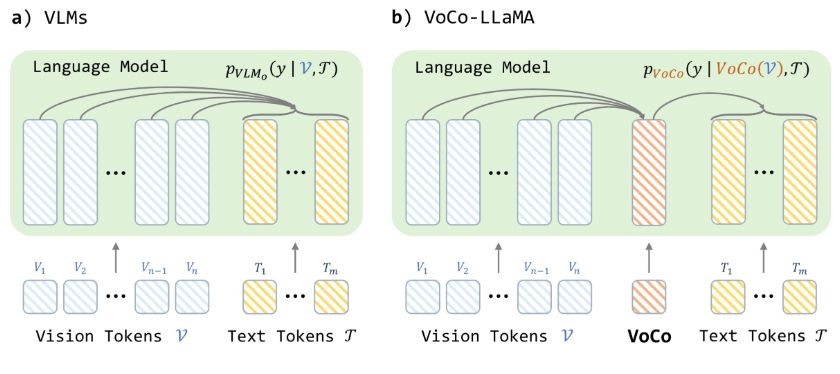
VoCo-LLaMA是一种利用大型语言模型(LLMs)实现视觉信息压缩的新方法。通过充分利用LLMs对视觉标记(vision tokens)的理解能力,VoCo-LLaMA能够将数百个视觉标记压缩成一个单一的VoCo标记,并将视觉信息损失降到最低。
这一方法通过对时间序列压缩后的视频帧标记序列进行持续训练,展示了其理解视频的能力。此外,VoCo-LLaMA还提供了一种解锁视觉语言模型(VLMs)上下文窗口全部潜力的新途径。
使用场景:
-
视频理解与分析: VoCo-LLaMA可以在视频数据中抽取关键信息,减少处理的数据量,从而加速视频分析和理解任务。这在监控、自动驾驶和视频推荐系统中具有显著意义。
-
图像语义理解: 在需要对大量图片进行语义分析的应用中,如医疗影像诊断、地理信息系统等,VoCo-LLaMA能够通过压缩视觉信息而提高处理效率。
-
跨模态信息融合: VoCo-LLaMA可以用于图像和文本的多模态模型,提升图文匹配、实时翻译及生成等任务的性能。
-
数据存储和传输: 通过对视觉信息进行高效压缩,VoCo-LLaMA可以在带宽受限的环境下(如太空探索、远程监控)提供高质量的数据传输解决方案。
总结:
VoCo-LLaMA通过结合大型语言模型和视觉压缩技术,提供了一种高效的视觉信息处理方法,适用于各种需要高效及时处理大规模视觉数据的场景,具有广泛的实际应用前景。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621