
ChatGLM.cpp
ChatGLM.cpp 简介
ChatGLM.cpp 是一种基于 C++ 的高效实现,用于执行包括 ChatGLM-6B、ChatGLM2-6B、ChatGLM3、GLM-4 以及其他大型语言模型(LLMs)的实时聊天和推断。该项目借鉴了 llama.cpp 的技术,通过使用 ggml 库实现了内存优化和高效的 CPU 推断,支持 int4/int8 量化、优化的 KV 缓存数据和并行计算。
主要特点
- 纯 C++ 实现:完全基于 ggml 库,类似于 llama.cpp 的工作方式。
- 内存高效:支持 int4/int8 量化,优化的 KV 缓存以及并行计算,极大降低内存需求。
- 多硬件支持:包括 x86 和 arm CPU、NVIDIA GPU 以及 Apple Silicon GPU。
- 多平台兼容:支持 Linux, MacOS, Windows。
- 流式生成:支持打字机效果的流式文本生成。
- 多种微调模型支持:P-Tuning v2 和 LoRA 微调模型。
- 支持 Python 接口和 API 服务器:可便捷地与 Python 集成,并且提供 Web 演示和 API 服务器。
使用场景
- 实时聊天机器人:可在桌面环境(如 MacBook)上部署,用于实现高效、实时的聊天功能。
- 软件开发和测试:可用于集成到现有的软件系统中,提供自然语言处理的能力。
- 模型推理服务:通过 API 服务器,可以为其他应用提供语言模型推理服务。
- 研究和开发:适用于研究和开发目的,特别是需要低内存占用和高效推理的场景。
快速开始
-
克隆仓库:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp -
安装必要的 Python 包:
python3 -m pip install -U pip python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece -
模型量化:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin -
编译项目:
cmake -B build cmake --build build -j --config Release -
运行模型:
./build/bin/main -m models/chatglm-ggml.bin -p 你好 -
开启交互模式:
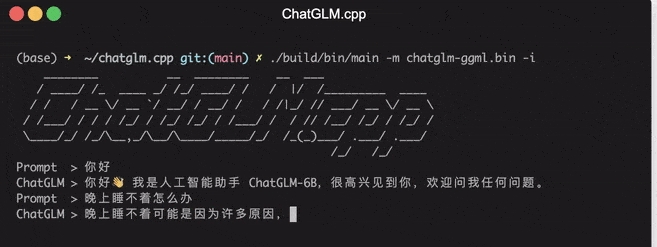
./build/bin/main -m models/chatglm-ggml.bin -i
通过上述简单的步骤,便可以在本地环境中快速部署 ChatGLM 模型,用于实时聊天和推理任务。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621