
Prometheus-Eval
Prometheus-Eval 简介
Prometheus-Eval 是一个专门用于评估生成任务中大型语言模型(LLMs)的工具库。该工具库集成了对语言模型进行训练、评估和应用的多种功能,并提供简便的Python接口来评估指令和响应对。Prometheus-Eval 的独特之处在于其开源的特性,提供了更高的公平性、可控性和经济性,不依赖于封闭源代码的评估模型。
使用场景
-
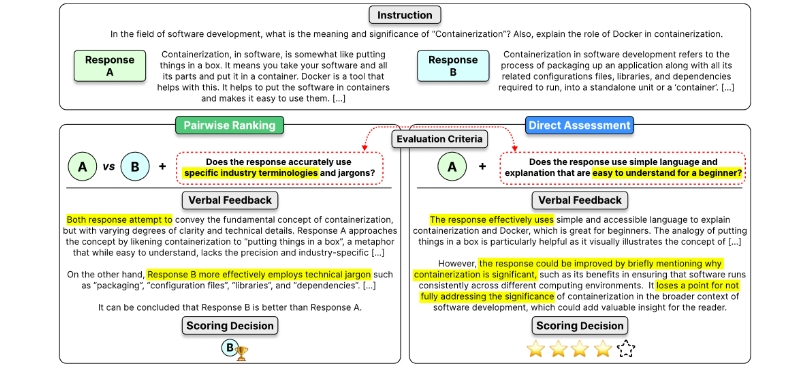
评估指令和响应对:Prometheus-Eval 可以通过绝对评分(absolute grading)和相对评分(relative grading)两种方式评估模型的响应质量。绝对评分为每个响应打分,范围为1到5;相对评分则在两个响应中选择更好的一个。
-
本地推理和API推理:该库支持通过
vllm在本地运行评估模型,同时也支持使用API(如GPT-4)进行模型推理。 -
模型训练和微调:Prometheus-Eval 提供了训练和微调语言模型的脚本,用户可以利用自定义数据集来训练Prometheus模型。
-
大规模批量评估:对于需要评估大量数据集的场景,Prometheus-Eval 也提供了批量评估功能,比单独评估每个响应更为高效。
-
高品质评估数据集:Prometheus 2 (7B & 8x7B) 模型基于BiGGen-Bench的数据集进行训练和评估,支持多种能力和任务,并提供详细的评估准则。
-
可视化和报告生成:Prometheus-Eval 允许用户生成交互式报告和可视化评分结果,便于分析评估结果。
安装和使用
-
安装:
pip install prometheus-eval -
本地推理与API推理:
-
本地推理需要安装
vllm:pip install vllm -
API推理可参考
litellm提供的安装细节。
-
-
快速开始:
from prometheus_eval.vllm import VLLM from prometheus_eval import PrometheusEval model = VLLM(model="prometheus-eval/prometheus-7b-v2.0") judge = PrometheusEval(model=model) instruction = "输入指令..." response = "模型响应..." reference_answer = "参考答案..." rubric = "评分准则..." feedback, score = judge.single_absolute_grade( instruction=instruction, response=response, rubric=rubric, reference_answer=reference_answer ) print("反馈:", feedback) print("评分:", score)
总结来说,Prometheus-Eval 为研究者和开发者提供了一个强大的工具来公平、可控且经济地评估大型语言模型的生成任务性能。同时,它提供了丰富的功能来支持多种评估方式,适用于学术研究、工业应用和数据分析等多种场景。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621