
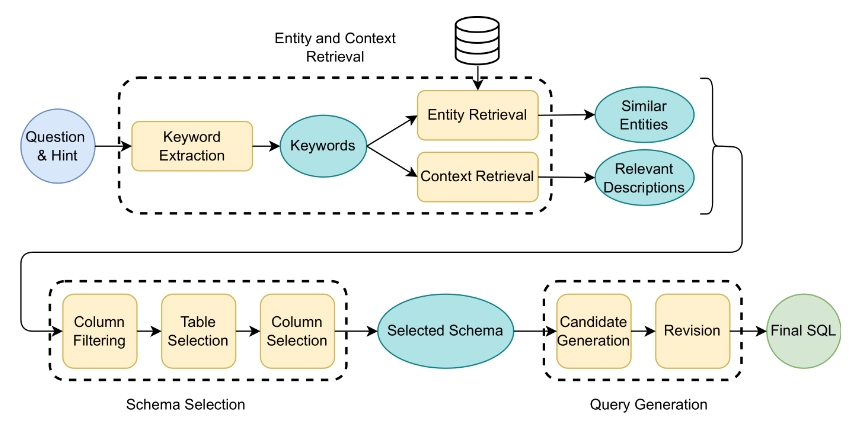
CHESS
CHESS(Contextual Harnessing for Efficient SQL Synthesis)是一种利用大规模语言模型(LLMs)将自然语言问题转换为SQL查询(text-to-SQL)的新方法,特别适用于具有复杂和广泛架构的实际数据库。传统方法在有效融合数据目录和数据库值生成SQL时存在困难,导致结果次优。为解决这些问题,CHESS提出了一个新管道,通过有效检索相关数据和上下文、选择高效模式并生成正确且高效的SQL查询,提升整体性能。
主要特性包括:
- 分层检索方法:利用模型生成的关键词、局部敏感哈希(LSH)索引和向量数据库,提高检索的精度。
- 自适应模式修剪:根据问题的复杂性和模型的上下文大小调整。
- 广泛适用性:适用于前沿的专有模型(如GPT-4)和开源模型(如Llama-3-70B)。
使用CHESS可以在多领域具有挑战性的BIRD数据集上实现新的性能记录。
使用场景
- 数据库问答:自动将用户用自然语言提出的问题转化为SQL查询,从而从数据库中获取答案。
- 数据分析:帮助数据科学家和分析师从复杂的数据库中高效检索相关数据。
- 企业内部工具:为企业开发内部工具,使非技术人员可以通过自然语言直接与公司的数据资产互动,而无需了解SQL。
- 教育培训:帮助SQL初学者理解如何将自然语言查询转化为SQL,提高学习效率。
设置和运行
- 环境配置:克隆仓库、创建配置文件(如添加OpenAI API密钥)并安装所需包。
- 数据预处理:更新预处理脚本路径,运行脚本为数据库创建minhash、LSH、和向量数据库。
- SQL生成:通过更新主要运行脚本路径,启动模型服务器,并运行生成SQL查询的脚本。
此外,系统还支持使用其他LLM,通过修改代码以集成自定义的LLM。
通过以上步骤,可以高效地实现SQL生成,并在各类数据检索和分析场景中应用CHESS。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621