
ComfyUI-B-LoRA
ComfyUI-B-LoRA 是 ComfyUI 的一个自定义节点,用于加载和应用 B-LoRA 模型。
什么是 B-LoRA?
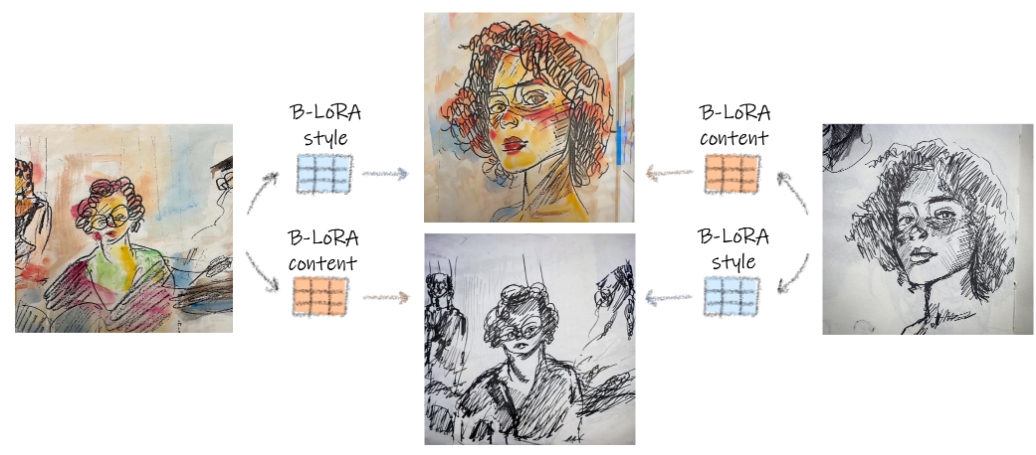
B-LoRA(Implicit Style-Content Separation using B-LoRA)是一种将单一图像隐式地分解为其样式和内容表示的方法。它可以高质量地进行样式和内容的混合,甚至可以在两个风格化的图像之间交换样式和内容。
- 官网:B-LoRA官网
- 代码库:GitHub - B-LoRA
- 当前 B-LoRA 模型仅适用于 SDXL 基础模型
sdxl_base_1.0,也可能兼容基于 SDXL 的微调模型,但不保证。
B-LoRA 的优势
- 可以单独应用“样式”或“内容”,或两者同时应用。
- 模型文件很小,大约100MB。
- 每个 B-LoRA 模型只需要一张图像作为训练数据,并且在单个 RTX 4090 上仅需15分钟即可完成训练。
用户可以在 Civit.ai 或 HuggingFace 上分享他们的 B-LoRA 模型。
B-LoRA 节点使用说明
加载 B-LoRA
lora_name: 选择你想加载的 B-LoRA 模型。默认情况下,会在models/loras/文件夹中搜索可用模型。load_style: 是否加载 B-LoRA 的样式。load_content: 是否加载 B-LoRA 的内容。strength: 设置 B-LoRA 对模型影响的强度。
使用场景
- 单节点加载 B-LoRA: 通过一个单独的加载节点应用一个 B-LoRA 模型,实现训练提示下的效果。
- 分别加载样式和内容: 通过两个不同的 B-LoRA 模型,一个用于样式,另一个用于内容,实现复杂的图像生成和风格转换。
示例工作流


预训练 B-LoRA 模型下载
可以在 HuggingFace 的 B-LoRA-examples 和 lora-library 下载。
训练你的 B-LoRA(进行中)
正在构建一个用于训练的 Docker 镜像,可以检查train目录查看当前进度。
参考文献
如果在研究中使用 B-LoRA,请引用以下论文:
@misc{frenkel2024implicit,
title={Implicit Style-Content Separation using B-LoRA},
author={Yarden Frenkel and Yael Vinker and Ariel Shamir and Daniel Cohen-Or},
year={2024},
eprint={2403.14572},
archivePrefix={arXiv},
primaryClass={cs.CV}
}

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621