
ComfyUI_EchoMimic
ComfyUI_EchoMimic 是一个集成在 ComfyUI 中的插件,主要功能是通过可编辑的标志物条件实现逼真的音频驱动的人像动画。该插件基于 EchoMimic 项目,可以生成同步音频和视频的人像动画。
使用场景
ComfyUI_EchoMimic 适用于需要将音频与人像动画同步的应用场景,例如:
- 虚拟主播: 根据音频内容生成虚拟主播的嘴型和面部表情,使得虚拟角色能够自然地与观众互动。
- 动画制作: 可以用于动画制作中,提升角色对话的自然性和真实感。
- 教育和培训: 根据预录音频制作教学视频,增强视频的吸引力和表现力。
安装步骤
-
下载插件: 在
./ComfyUI/custom_node目录下运行以下命令:git clone https://github.com/smthemex/ComfyUI_EchoMimic.git -
安装依赖:
pip install -r requirements.txt或者:
pip uninstall torchaudio torchvision torch xformers pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu121 pip install xformers==0.0.24 pip install facenet_pytorch pip uninstall ffmpeg pip install ffmpeg-python
模型文件
将所需的模型文件下载并放置在 ComfyUI/models/echo_mimic 目录下:
-
基本模型:
unetdiffusion_pytorch_model.binconfig.json
audio_processorwhisper_tiny.pt
denoising_unet.pthface_locator.pthmotion_module.pthreference_unet.pth
-
姿态驱动算法模型(可选)
unetdiffusion_pytorch_model.binconfig.json
audio_processorwhisper_tiny.pt
denoising_unet_pose.pthface_locator_pose.pthmotion_module_pose.pthreference_unet_pose.pth
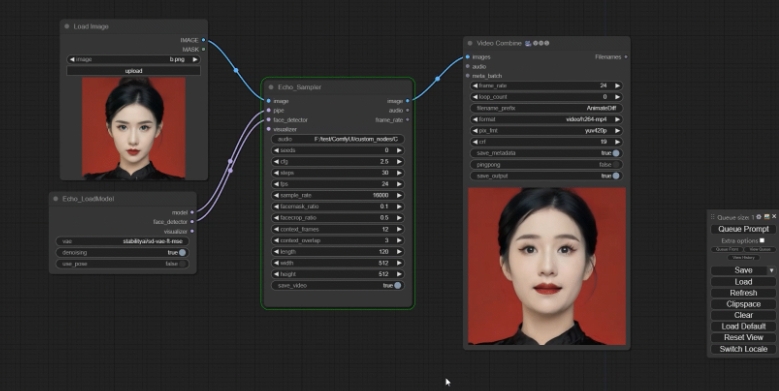
示例
- 音频驱动人像动画示例:

- 姿态驱动示例:

引用
如果在学术研究中使用了 EchoMimic,请引用以下文献:
@misc{chen2024echomimic,
title={EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditioning},
author={Zhiyuan Chen, Jiajiong Cao, Zhiquan Chen, Yuming Li, Chenguang Ma},
year={2024},
archivePrefix={arXiv},
primaryClass={cs.CV}
}

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621