
Scaling Diffusion Transformers with Mixture of Experts
Scaling Diffusion Transformers with Mixture of Experts (DiT-MoE)
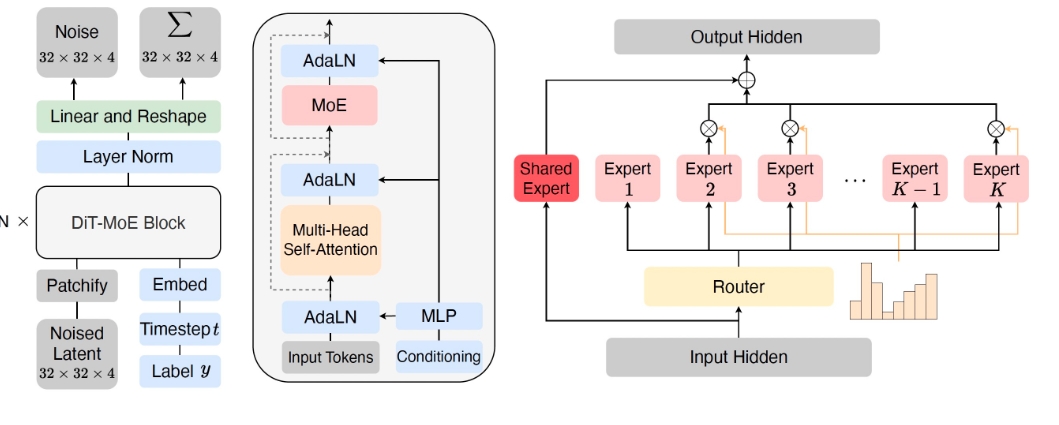
简介: Scaling Diffusion Transformers with Mixture of Experts (DiT-MoE) 通过将Diffusion Transformer与专家混合模型(MoE)结合,构建了一个稀疏版本的扩散Transformer,能够扩展到160亿参数。DiT-MoE在推理阶段具有高度优化的性能,且能够在性能上与稠密网络竞争。
主要内容:
- 模型实现: 提供了DiT-MoE的PyTorch实现。
- 预训练权重: 提供了论文中的预训练模型检查点。
- 采样脚本: 提供了用于运行预训练DiT-MoE模型的采样脚本。
- 训练脚本: 提供了使用PyTorch分布式数据并行(DDP)和DeepSpeed的训练脚本。
使用场景:
- 图像生成: DiT-MoE可以用来生成高质量的图像,例如从ImageNet数据集生成的图像。
- 大规模模型训练: 可以对大规模数据集进行训练,适用于需要高效推理的大模型。
- 分布式训练与优化: 能够利用多节点分布式训练技术,加快模型训练速度,适用于深度学习研究机构和企业。
- 特定任务的专家模型: 通过专家混合模型,可以训练特定任务的子模型,提高特定任务的性能。
具体使用说明:
-
训练:
- 单节点示例:
torchrun --nnodes=1 --nproc_per_node=N train.py \ --model DiT-S/2 \ --num_experts 8 \ --num_experts_per_tok 2 \ --data-path /path/to/imagenet/train \ --image-size 256 \ --global-batch-size 256 \ --vae-path /path/to/vae- 多节点示例:
torchrun --nnodes=8 \ --node_rank=0 \ --nproc_per_node=8 \ --master_addr="10.0.0.0" \ --master_port=1234 \ train.py \ --model DiT-B/2 \ --num_experts 8 \ --num_experts_per_tok 2 \ --global-batch-size 1024 \ --data-path /path/to/imagenet/train \ --vae-path /path/to/vae -
推理:
python sample.py \ --model DiT-XL/2 \ --ckpt /path/to/model \ --vae-path /path/to/vae \ --image-size 256 \ --cfg-scale 1.5
未来计划:
- 提供状态检查点给HuggingFace。
- 发布合成数据。
引用: 如果使用此代码或模型,请引用以下文章:
@article{FeiDiTMoE2024,
title={Scaling Diffusion Transformers to 16 Billion Parameters},
author={Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, Jusnshi Huang},
year={2024},
journal={arXiv preprint},
}

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621