
E5-V
E5-V: 带有多模态大语言模型的通用嵌入框架
概述
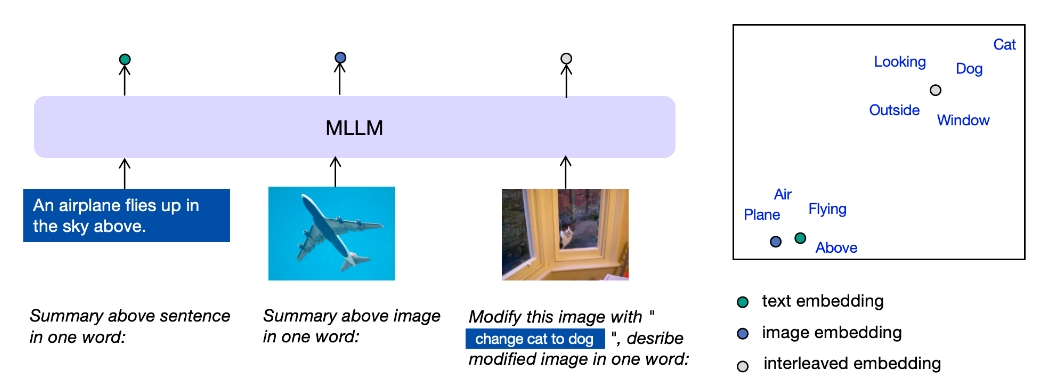
E5-V是一个框架,旨在将多模态大语言模型(MLLMs)适配用于多模态嵌入。E5-V有效地弥合了不同类型输入之间的模态差距,即使在没有微调的情况下,也能在多模态嵌入方面表现出色。我们还提出了一种单一模态训练的方法,该方法仅在文本对上进行训练,表明其性能优于多模态训练。
使用场景
E5-V适用于各种多模态任务,包括但不限于:
- 图像和文本的相互检索:例如在COCO和Flickr30k数据集上的图文检索任务。
- 图像到图像的检索:如在i2i-coco和i2i-flickr30k数据集上的任务。
- 语义相似性计算:在STS(语义文本相似性)任务中的应用。
具体示例
示例代码展示了如何使用E5-V模型进行图像和文本的嵌入计算,并且可以相互做相似度检索。
import torch
import torch.nn.functional as F
import requests
from PIL import Image
from transformers import AutoTokenizer
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
llama3_template = '<|start_header_id|>user<|end_header_id|>\n\n{}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n \n'
processor = LlavaNextProcessor.from_pretrained('royokong/e5-v')
model = LlavaNextForConditionalGeneration.from_pretrained('royokong/e5-v', torch_dtype=torch.float16).cuda()
img_prompt = llama3_template.format('<image>\nSummary above image in one word: ')
text_prompt = llama3_template.format('<sent>\nSummary above sentence in one word: ')
urls = ['https://upload.wikimedia.org/wikipedia/commons/thumb/4/47/American_Eskimo_Dog.jpg/360px-American_Eskimo_Dog.jpg',
'https://upload.wikimedia.org/wikipedia/commons/thumb/b/b6/Felis_catus-cat_on_snow.jpg/179px-Felis_catus-cat_on_snow.jpg']
images = [Image.open(requests.get(url, stream=True).raw) for url in urls]
texts = ['A dog sitting in the grass.',
'A cat standing in the snow.']
text_inputs = processor([text_prompt.replace('<sent>', text) for text in texts], return_tensors="pt", padding=True).to('cuda')
img_inputs = processor([img_prompt]*len(images), images, return_tensors="pt", padding=True).to('cuda')
with torch.no_grad():
text_embs = model(**text_inputs, output_hidden_states=True, return_dict=True).hidden_states[-1][:, -1, :]
img_embs = model(**img_inputs, output_hidden_states=True, return_dict=True).hidden_states[-1][:, -1, :]
text_embs = F.normalize(text_embs, dim=-1)
img_embs = F.normalize(img_embs, dim=-1)
print(text_embs @ img_embs.t())
上述代码展示了如何加载和使用预训练的E5-V模型来处理图像和文本输入,并生成标准化的嵌入向量用于相似度计算。
评价和训练
提供了多种评价方式和具体的训练步骤,以便于在不同数据集上测试和训练模型。包括安装依赖、下载数据、模型格式转换、训练和测试的详细命令步骤。
通过这些示例和使用场景,E5-V框架展示了其在多模态环境下强大的嵌入能力和广泛的应用前景。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621