
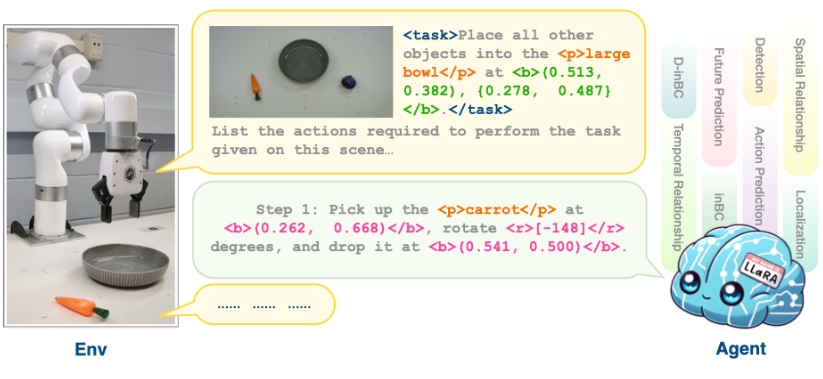
LLaRA
LLaRA (Large Language and Robotics Assistant) 是一个旨在提升机器人学习数据的视觉-语言策略系统。该项目的主要贡献在于结合先进的视觉和语言模型(如LLaVA)以及机器人操作数据(VIMABench),从而实现更高效的机器人学习和操作。
使用场景
LLaRA具有广泛的应用场景:
- 机器人学习和强化学习:通过提供高质量的视觉和语言数据,LLaRA可以帮助机器人更好地理解和执行复杂任务。
- 自动化操作:能够在工业自动化、家务机器人等领域中,提高机器人对环境的理解和任务执行能力。
- 人机交互:通过自然语言处理和视觉识别技术,LLaRA可以用于开发更智能、更直观的人机交互系统。
- 学术研究:为机器人学习和人工智能研究者提供一个高效的数据训练和评估平台。
安装与使用指南
- 环境配置:
- 跟随LLaVA的环境安装说明进行Python环境设置。
- 安装VIMABench:
- 设置VIMABench以使用其功能。
- 下载预训练模型:
- 将预训练模型下载到
./checkpoints/目录中。
- 将预训练模型下载到
- 评估模型:
- 使用脚本
eval-llara.py进行评估,并将结果保存到指定位置。
- 使用脚本
- 数据集准备与模型微调:
- 准备数据集,并按照说明微调LLaVA模型,最终评估训练的模型效果。
支持与反馈
如果在使用过程中遇到任何问题,用户可以在项目的GitHub issues页面提交问题。
许可信息
该项目根据Apache-2.0 License授权,具体细节可参见LICENSE文件。
研究引用
如果该项目对您的研究有帮助,请考虑引用他们的工作。相关的引用格式已在项目主页提供。
通过上述介绍,希望您对LLaRA有一个清晰的了解,并能够在您的机器人和AI项目中有效地应用。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621