
MambaVision
MambaVision 简介
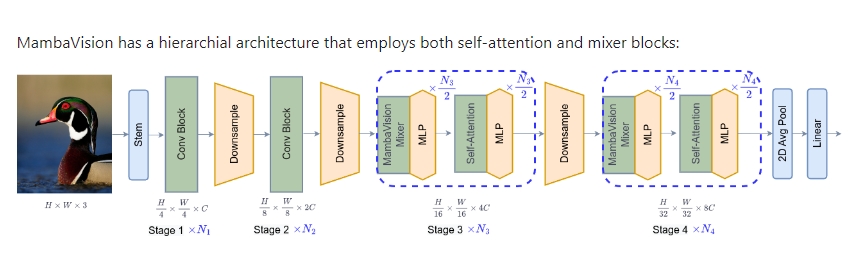
MambaVision 是一种混合型的 Mamba-Transformer 视觉骨干网络,由 Ali Hatamizadeh 和 Jan Kautz 提出并开发。它通过结合自注意力机制和混合块(mixer blocks),呈现出一种层次化的架构设计,从而提升了全局上下文的建模能力,并取得了顶尖的性能表现。MambaVision 在 Top-1 准确率和吞吐量方面达到了新的状态-先进(SOTA)水平。
使用场景
MambaVision 主要适用于图像分类任务,但是其结构也可以应用于其他视觉任务,如目标检测和图像分割。此外,预训练的 MambaVision 模型可以通过简单的代码导入,为各种计算机视觉应用提供高效的解决方案。详细使用方法如下:
图像分类
-
安装预训练模型及依赖包
pip install mambavision -
加载并使用模型
from mambavision import create_model model = create_model('mamba_vision_T', pretrained=True, model_path="/tmp/mambavision_tiny_1k.pth.tar") import torch image = torch.rand(1, 3, 224, 224).cuda() # 示例输入图像 model = model.cuda() output = model(image) # 输出 logits -
进行模型验证
python validate_pip_model.py --model mamba_vision_T --data_dir=$DATA_PATH --batch-size $BS
结果与性能
在 ImageNet-1K 数据集上,MambaVision 各个预训练模型的表现如下:
| 模型名称 | Top-1 准确率 (%) | Top-5 准确率 (%) | 吞吐量 (图片/秒) | 输入分辨率 | 参数量 (M) | FLOPs (G) | 下载链接 |
|---|---|---|---|---|---|---|---|
| MambaVision-T | 82.3 | 96.2 | 6298 | 224x224 | 31.8 | 4.4 | 链接 |
| MambaVision-T2 | 82.7 | 96.3 | 5990 | 224x224 | 35.1 | 5.1 | 链接 |
| MambaVision-S | 83.3 | 96.5 | 4700 | 224x224 | 50.1 | 7.5 | 链接 |
| MambaVision-B | 84.2 | 96.9 | 3670 | 224x224 | 97.7 | 15.0 | 链接 |
| MambaVision-L | 85.0 | 97.1 | 2190 | 224x224 | 227.9 | 34.9 | 链接 |
| MambaVision-L2 | 85.3 | 97.2 | 1021 | 224x224 | 241.5 | 37.5 | 链接 |
其他说明
MambaVision 的代码和预训练模型权重已公开,用户可以在他们自己的项目中使用这些权重。模型采用 NC 许可,细节请参阅 LICENSE 文档。MambaVision 的开发基于高质量的 timm 库,对于该库的使用也提供了详细的感谢页面。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621