
OpenVPRLab
OpenVPRLab 是一个全面的开源框架,专注于视觉地点识别(Visual Place Recognition, VPR)。该框架旨在帮助研究人员和开发人员训练和迭代开发深度模型,以简化实现可复制的最先进(SOTA)性能的过程。
使用场景
- 研究和开发: 轻松开发和测试新的视觉地点识别技术。
- 训练和微调: 测试、训练或微调现有的最先进方法。
- 教育: 为进入视觉地点识别领域的新手提供实操学习体验。
特点
- 简单的数据集管理: 只需一条命令即可下载例如
GSV-Cities和GSV-Cities-light等数据集,便于立即开始实验。 - 高度模块化的设计: 提供简单有效的训练架构
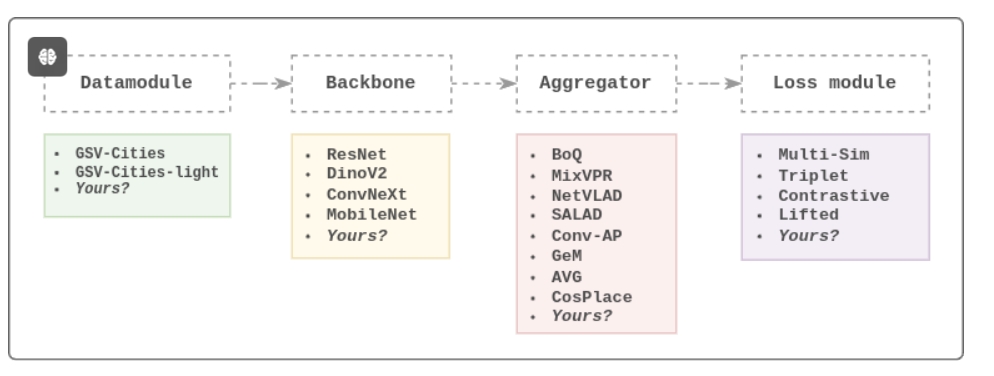
[Data] -> [Backbone] -> [Aggregation] -> [Loss],便于用户构建自己的聚合器、骨干网络、损失函数等组件。 - 丰富的损失函数: 提供多个深度度量学习相关的损失函数,助力高级模型优化和实验。
- 集成Tensorboard支持: 跟踪和可视化训练过程。
- 模型性能可视化: 包括召回率图、检索失败预览、注意力图等。
安装步骤
-
克隆存储库:
git clone https://github.com/amaralibey/OpenVPRLab.git cd OpenVPRLab -
创建环境并安装依赖:
conda env create -f environment.yml conda activate openvpr
快速上手
-
下载数据集:
python scripts/datasets_downloader.py -
测试框架:
python run.py --dev -
训练模型:
创建或修改配置文件(例如
config/sample_model_config.yaml),然后运行:python run.py --config ./config/resnet50_mixvpr.yaml -
使用Tensorboard监控训练:
tensorboard --logdir ./logs/
开发你的VPR聚合器
-
创建聚合器文件(例如
my_agg.py)并放置在src/models/aggregators/路径下。import torch class ConvAP(torch.nn.Module): def __init__(self, in_channels=1024, out_channels=512, s1=2, s2=2): super().__init__() self.channel_pool = torch.nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1) self.AAP = torch.nn.AdaptiveAvgPool2d((s1, s2)) def forward(self, x): x = self.channel_pool(x) x = self.AAP(x) x = torch.nn.functional.normalize(x.flatten(1), p=2, dim=1) return x -
将聚合器集成到
__init__.py文件中:from .mixvpr import MixVPR from .boq import BoQ from .my_agg import ConvAP -
运行训练实验:
命令行直接控制超参数:
python run.py --backbone ResNet --aggregator ConvAP --batch_size 60 --lr 0.0001 -
创建并使用配置文件:
示例配置文件
my_model_config.yaml中包括所有的超参数设置,然后运行:python run.py --config ./config/my_model_config.yaml -
监控实验进展:
模型权重和所有超参数将会保存在
logs/目录下,可以用Tensorboard进行可视化:tensorboard --logdir ./logs/resnet18/ConvAP
更多教程和方法
未来将会有更多的功能、教程和方法逐步补充。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621