
PDF-Extract-Kit
PDF-Extract-Kit 简介
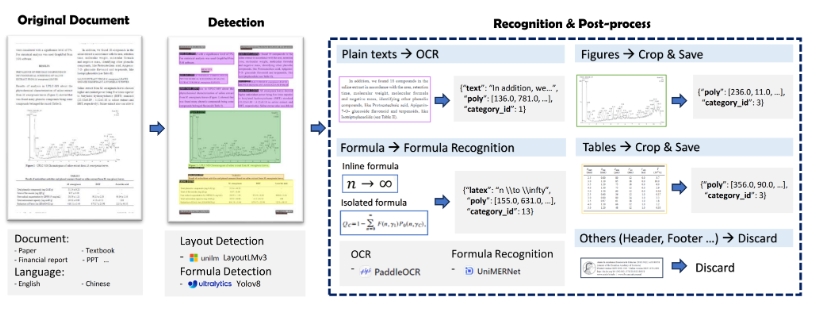
PDF-Extract-Kit旨在解决PDF文档内容抽取中的难题,通过以下功能模块实现高质量内容提取:
- 版面检测:使用 LayoutLMv3 模型进行区域检测,如检测图片、表格、标题、文本等。
- 公式检测:使用 YOLOv8 模型检测公式,包括行内公式和独立公式。
- 公式识别:使用 UniMERNet 进行公式识别。
- 光学字符识别 (OCR):使用 PaddleOCR 进行文本识别。
注意:由于文档类型的多样性,现有的开源版面和公式检测模型在应对多样化的PDF文档时存在困难。因此,我们收集了多样化的数据进行标注和训练,以便在各种文档类型上实现精确的检测效果。
PDF内容提取框架如下图所示:

PDF-Extract-Kit输出格式如下:
{
"layout_dets": [
{
"category_id": 0,
"poly": [136.0, 781.0, 340.0, 781.0, 340.0, 806.0, 136.0, 806.0],
"score": 0.69,
"latex": ''
},
...
],
"page_info": {
"page_no": 0,
"height": 1684,
"width": 1200
}
}
category_id 包含的类型如下:
{0: 'title', 1: 'plain text', 2: 'abandon', 3: 'figure', 4: 'figure_caption', 5: 'table', 6: 'table_caption', 7: 'table_footnote', 8: 'isolate_formula', 9: 'formula_caption', 13: 'inline_formula', 14: 'isolated_formula', 15: 'ocr_text'}
使用场景
PDF-Extract-Kit适用于多种场景的PDF文档内容提取,包括但不限于:
- 学术论文:提取论文中的标题、表格、图片、公式等。
- 教科书:提取教科书中的章节标题、表格、图片、公式等。
- 研究报告:提取研究报告中的文本、图表、公式等。
- 财务报表:提取财务报表中的表格、标题、文本等内容。
- 其他文档类型:适用于各种类型的PDF文档,不论是否含有水印或扫描模糊。
评价指标
版面检测
在各种验证集上,我们的版面检测模型相对于其他开源模型表现出色,尤其是训练了多样化数据后效果显著提升。
公式检测
通过训练我们自己的YOLOv8模型,公式检测在不同验证集上也表现出色,相对于现有的开源公式检测模型有明显的优势。
安装与运行
可按照以下步骤进行安装:
conda create -n pipeline python=3.10
pip install -r requirements.txt
pip install --extra-index-url https://miropsota.github.io/torch_packages_builder detectron2==0.6+pt2.3.1cu121
运行PDF内容提取脚本:
python pdf_extract.py --pdf data/pdfs/ocr_1.pdf
参数说明:
--pdf: 要处理的PDF文件或文件夹。--output: 保存结果的路径,默认为 “output”。--vis: 是否可视化结果。--render: 是否渲染识别结果(包括LaTeX代码和纯文本)。
许可证
本项目依 Apache-2.0 License 发布,使用对应模型权重时需遵循相应的模型许可证。
鸣谢
感谢以下开源项目的支持:

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621