
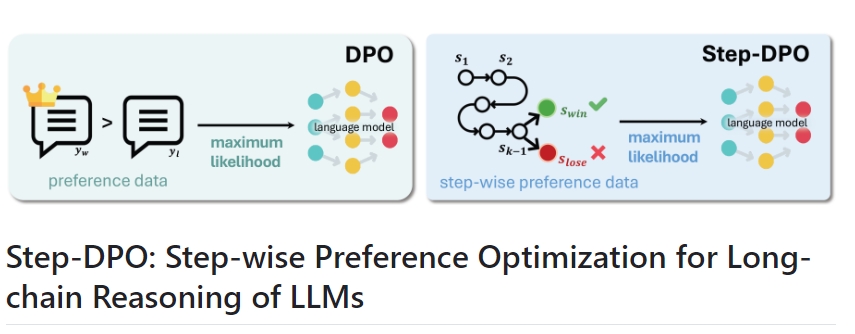
Step-DPO
Step-DPO是一种用于增强大规模语言模型(LLMs)长链推理能力的简单、有效且数据高效的方法。它通过构建包含10K步骤偏好对的高质量数据集来实现这一目的。在有限的数据和训练步骤下,Step-DPO显著提升了模型在MATH和GSM8K上的表现。
Step-DPO的基本工作原理:
- 数据构建:创建一个包含10K步骤偏好对的高质量数据集。
- 训练方法:使用少量的数据和数百个训练步骤,对预训练模型进行微调。
成果和性能:
- Qwen2-7B-Instruct模型在MATH数据集上的性能从53.0%提升到58.6%,在GSM8K上的性能从85.5%提升到87.9%。
- Qwen2-72B-Instruct模型在MATH数据集上取得70.8%的成绩,在GSM8K上取得94.0%的成绩,超越了许多闭源模型如GPT-4-1106、Claude-3-Opus和Gemini-1.5-Pro。
使用场景:
- 数学推理:适用于需要长链推理能力的数学问题解决,如MATH和GSM8K测试集。
- 模型优化:能够有效提升各种基础模型的性能,包括Qwen、DeepSeekMath等不同大小和版本的模型。
- 开源与闭源模型对比:可以在现有的开源模型基础上进行微调,超越一些闭源的高级模型。
安装与训练:
- 安装:
conda create -n step_dpo python=3.10 conda activate step_dpo pip install -r requirements.txt - 预训练权重:使用Qwen2、Qwen1.5、Llama-3、DeepSeekMath等模型进行微调。
- 微调例子:
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file accelerate_configs/deepspeed_zero3_cpu.yaml --mixed_precision bf16 \ --num_processes 8 \ train.py configs/config_full.yaml \ --model_name_or_path="Qwen/Qwen2-72B-Instruct" \ --data_path="xinlai/Math-Step-DPO-10K" \ --per_device_train_batch_size=2 \ --gradient_accumulation_steps=8 \ --torch_dtype=bfloat16 \ --bf16=True \ --beta=0.4 \ --num_train_epochs=4 \ --save_strategy='steps' \ --save_steps=200 \ --save_total_limit=1 \ --output_dir=outputs/qwen2-72b-instruct-step-dpo \ --hub_model_id=qwen2-72b-instruct-step-dpo \ --prompt=qwen2-boxed
评估:
- 在GSM8K测试集上的评估:
python eval_math.py \ --model outputs/qwen2-72b-instruct-step-dpo \ --data_file ./data/test/GSM8K_test_data.jsonl \ --save_path 'eval_results/gsm8k/qwen2-72b-instruct-step-dpo.json' \ --prompt 'qwen2-boxed' \ --tensor_parallel_size 8 - 在MATH测试集上的评估:
python eval_math.py \ --model outputs/qwen2-72b-instruct-step-dpo \ --data_file ./data/test/MATH_test_data.jsonl \ --save_path 'eval_results/math/qwen2-72b-instruct-step-dpo.json' \ --prompt 'qwen2-boxed' \ --tensor_parallel_size 8
Step-DPO通过简单的优化策略,大幅提升了LLMs在长链推理任务中的表现,适用于多种复杂的推理和问题解决场景。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621