
UniSeg3D
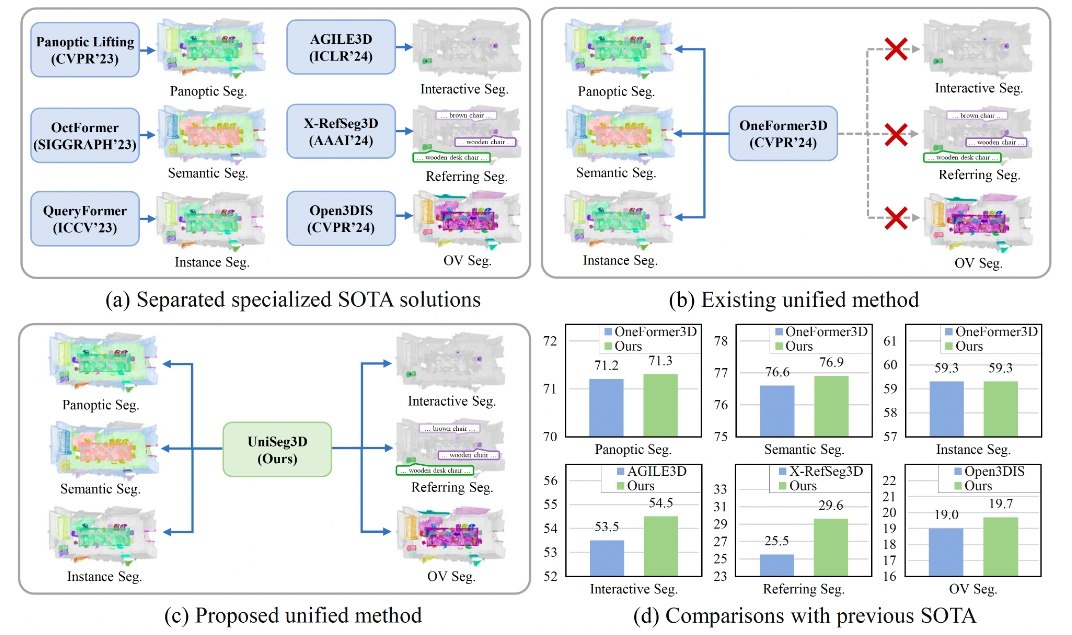
UniSeg3D是一个统一的3D场景理解框架,能够在单一模型中实现全景细分、语义分割、实例分割、交互式分割、指向性分割以及开放词汇语义分割六项任务。这一框架突破了以往3D分割方法专门针对某一特定任务的局限,通过将六个任务统一到同一套表示系统中处理来促进任务间的知识共享,从而实现对3D场景的全面理解。利用这种多任务统一的方法,UniSeg3D通过设计知识蒸馏方法和对比学习方法,将特定任务的知识在不同任务间进行转移,显著提升性能。实验结果表明,在ScanNet20、ScanRefer和ScanNet200三个基准测试中,UniSeg3D在各项任务上都超越了当前的最新方法。
使用场景
- 全景分割(Panoptic Segmentation,PS):主流场景理解任务之一,结合了语义分割和实例分割,适用于机器人视觉、自动驾驶等场景。
- 语义分割(Semantic Segmentation,SS):对场景中的每一个像素进行分类,适用于计算机视觉、医学影像分析等。
- 实例分割(Instance Segmentation,IS):在语义分割的基础上还要区分出不同的实例对象,应用于对象检测、增强现实等。
- 交互式分割(Interactive Segmentation):用户可以与系统交互来指定需要分割的对象,在图像编辑、精细化标注中有广泛应用。
- 指向性分割(Referring Segmentation):根据自然语言的描述来分割出指定的对象,适用于人机交互、语音助手等情境。
- 开放词汇语义分割(Open-Vocabulary Semantic Segmentation,OVS):能识别词汇库之外的物体类别,适用于需要泛化能力的实际应用场景。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621