
VISA
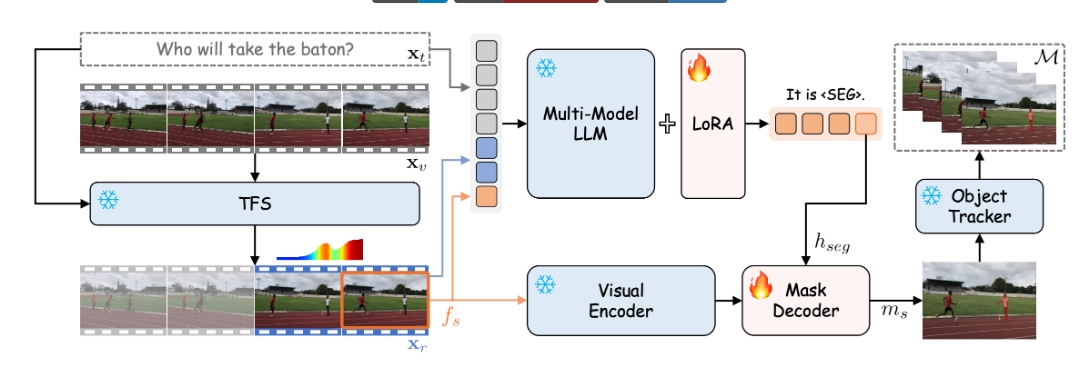
VISA(Video Object Segmentation via Large Language Model)是一个利用大型语言模型进行视频目标分割的系统。VISA在应对复杂分割任务方面表现出色,这些任务需要(a)基于世界知识进行推理,(b)推断未来事件,以及(c)对视频内容有全面理解。
使用场景
VISA 可以应用在多种复杂的场景,例如:
- 推理与场景理解:利用世界知识对视频中的内容进行逻辑推理,分析和理解不同情景下的物体和事件。
- 未来事件预测:从视频中推断出可能会发生的未来事件,例如预测运动轨迹或行为模式。
- 视频内容分析:对视频内容进行详细且全面的分析,包括识别和分割其中的物体和场景。
性能展示
VISA在推理分割任务上展示了卓越的性能,能够处理需要深度理解和推理的视频分割问题。
安装与使用
VISA的安装比较简单,通过以下命令即可安装所需依赖:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
接下来,可以根据不同的数据集准备训练数据,并下载预训练权重,然后启动训练和验证过程。
训练与验证
- 数据准备:从不同来源下载和配置所需的数据集。
- 预训练权重:下载Chat-UniVi和SAM的预训练权重。
- 训练过程:配置和启动训练脚本,进行模型训练。
- 验证过程:运行验证脚本对模型性能进行评估。
引用
如果您在研究中使用了VISA,请引用以下论文:
@article{yan2024visa,
title={VISA: Reasoning Video Object Segmentation via Large Language Models},
author={Yan, Cilin and Wang, Haochen and Yan, Shilin and Jiang, Xiaolong and Hu, Yao and Kang, Guoliang and Xie, Weidi and Gavves, Efstratios},
journal={arXiv preprint arXiv:2407.11325},
year={2024}
}

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621