
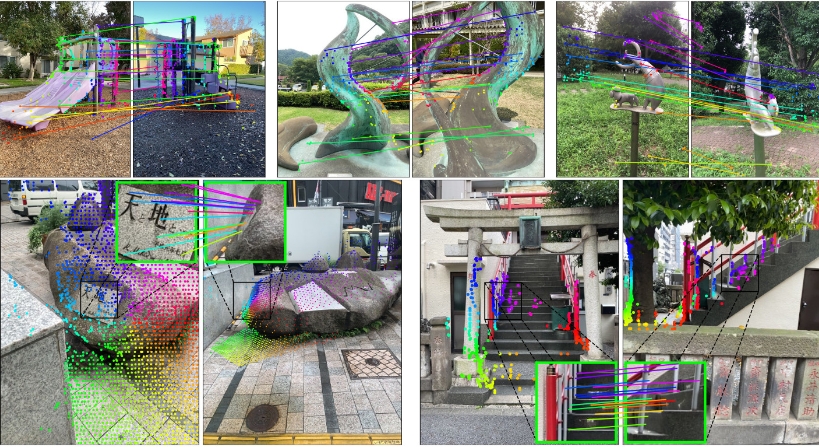
mast3r
MASt3R(Grounding Image Matching in 3D with MASt3R)是一种结合3D几何和图像匹配的视觉算法模型,主要用于图像配准和三维重建等计算机视觉任务。通过在3D空间中对图像进行匹配,MASt3R能够在不同视角和条件下实现高精度的图像配准。
使用场景
- 视觉定位(Visual Localization):MASt3R能够有效地用于视觉定位任务,通过匹配图像中同一物体的不同视角,推断出相机的实际位置和姿态。
- 三维重建(3D Reconstruction):通过多视角图像的匹配,MASt3R可以用于重建三维场景,为AR/VR和机器人导航提供基础数据。
- 图像配准(Image Registration):在不同视角下将图像对齐,用于医学影像、地理信息系统等领域。
- 环境感知(Environmental Sensing):用于自动驾驶和无人机导航,通过图像匹配进行环境的三维感知和建模。
- 增强现实(Augmented Reality, AR):通过精准的图像匹配和三维定位,为增强现实应用提供稳定的空间参考。
MASt3R 的技术细节
- 架构:MASt3R采用了一种非对称架构,包含一个编码器和多个解码器,并使用RoPE(Rotary Position Embedding)位置嵌入进行增强。
- 实现步骤:
- 数据准备:对训练和测试数据集进行预处理,支持多个公共数据集如CO3Dv2, BlendedMVS, MegaDepth等。
- 训练:使用多种损失函数(如ConfLoss, Regr3D)和优化策略进行模型训练。
- 推理:通过demo和示例代码,展示了如何使用预训练模型进行图像匹配和三维重建。
- 视觉定位:提供了详细的例子说明如何应用于Aachen-Day-Night, InLoc, Cambridge Landmarks和7 Scenes等基准数据集的视觉定位任务。
安装和使用
- 安装:通过克隆仓库并安装必要的依赖项,配置好环境后编译CUDA内核加速运行。
- 模型检查点:支持通过HuggingFace Hub或直接下载预训练模型。
- 交互式演示:提供了多种形式的交互式演示脚本,帮助用户快速上手。
- 训练:提供了详细的训练指南和超参数设定,以便进行定制训练。
核心代码示例
from mast3r.model import AsymmetricMASt3R
from mast3r.fast_nn import fast_reciprocal_NNs
import mast3r.utils.path_to_dust3r
from dust3r.inference import inference
from dust3r.utils.image import load_images
if __name__ == '__main__':
device = 'cuda'
model_name = "naver/MASt3R_ViTLarge_BaseDecoder_512_catmlpdpt_metric"
model = AsymmetricMASt3R.from_pretrained(model_name).to(device)
images = load_images(['path_to_image1.png', 'path_to_image2.png'], size=512)
output = inference([tuple(images)], model, device, batch_size=1, verbose=False)
# 后续处理和显示匹配结果
MASt3R作为基于3D几何和视觉匹配的强大模型,在多视角图像处理和三维场景重建中展现了优异的性能和广泛的应用前景。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621