
RAG with txtai
RAG with txtai 是一个基于 Streamlit 的应用程序,通过 txtai 实现检索增强生成(Retrieval Augmented Generation,RAG)。RAG 能够通过限制大语言模型(LLM)生成答案的上下文,帮助生成事实正确的内容。这通常通过搜索查询来实现,以提供相关的上下文。
该应用程序支持两类 RAG:
- 向量 RAG:通过向量搜索查询获取上下文。
- 图 RAG:通过图路径遍历查询获取上下文。
快速启动
可以通过 Docker 容器或 Python 虚拟环境运行该应用程序。推荐首先使用 Docker 了解应用的功能。
Docker
在 Docker Hub 提供的 neuml/rag 镜像,可以使用以下命令运行:
docker run -d --gpus=all -it -p 8501:8501 neuml/rag
Python 虚拟环境
直接使用 Python 安装并运行:
pip install -r requirements.txt
streamlit run rag.py
演示
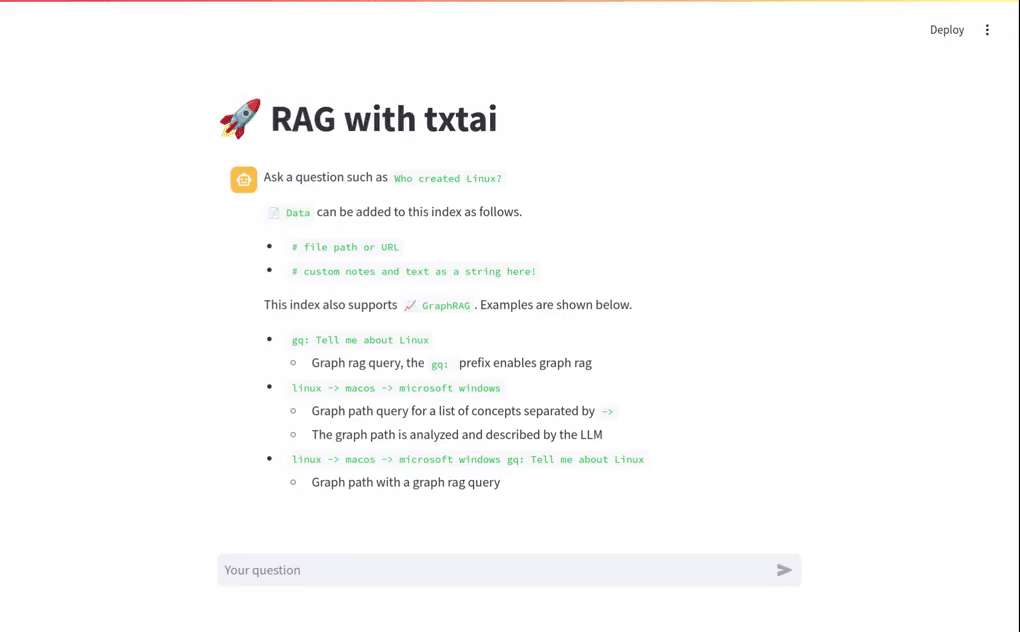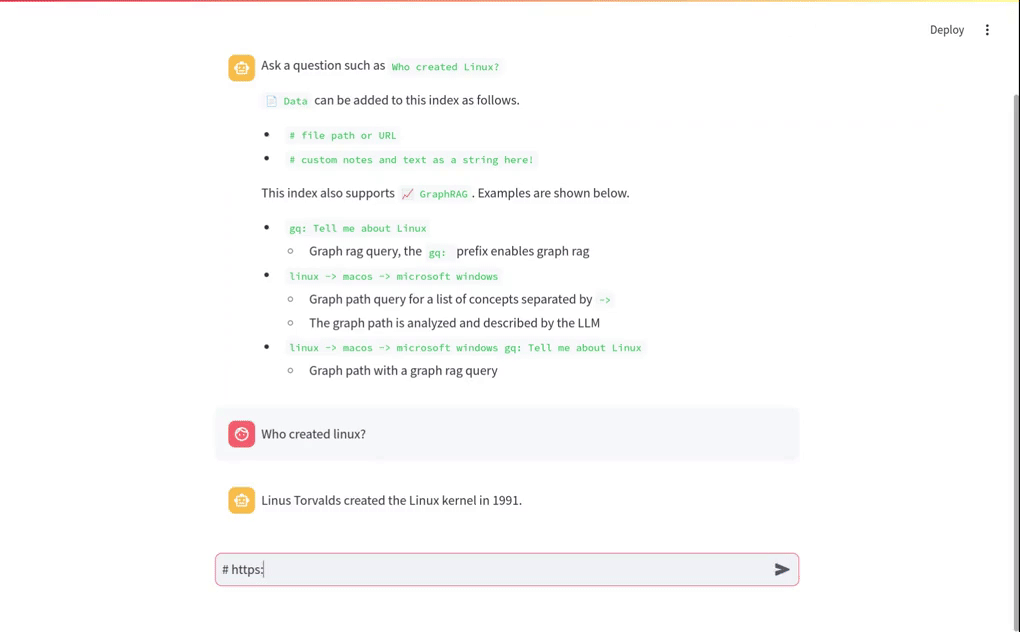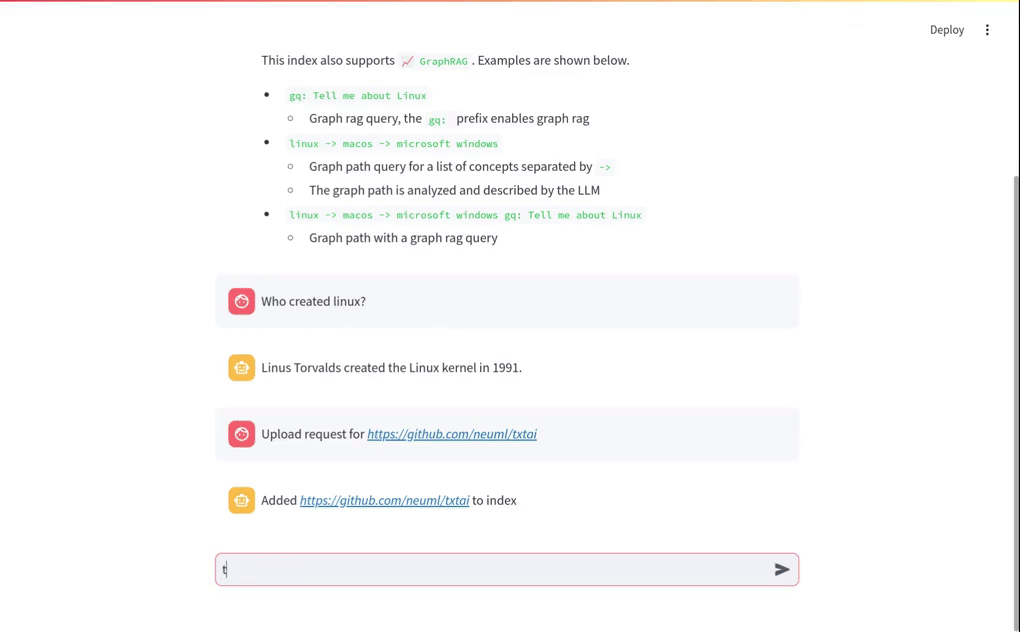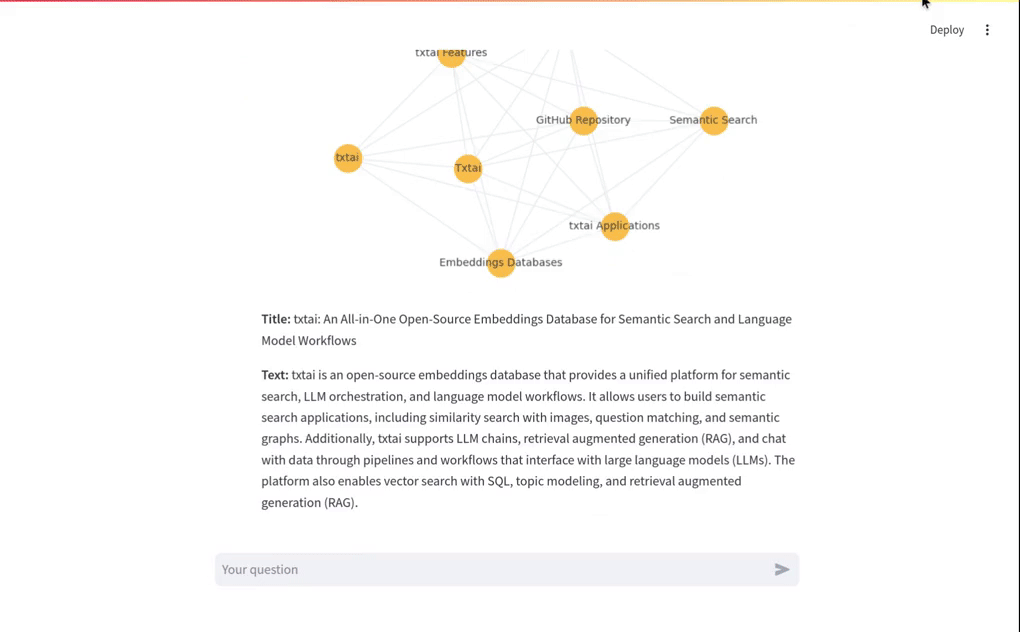
该视频演示了 RAG 系统的基本操作,包括向量 RAG 查询和图 RAG 查询。
RAG 详情
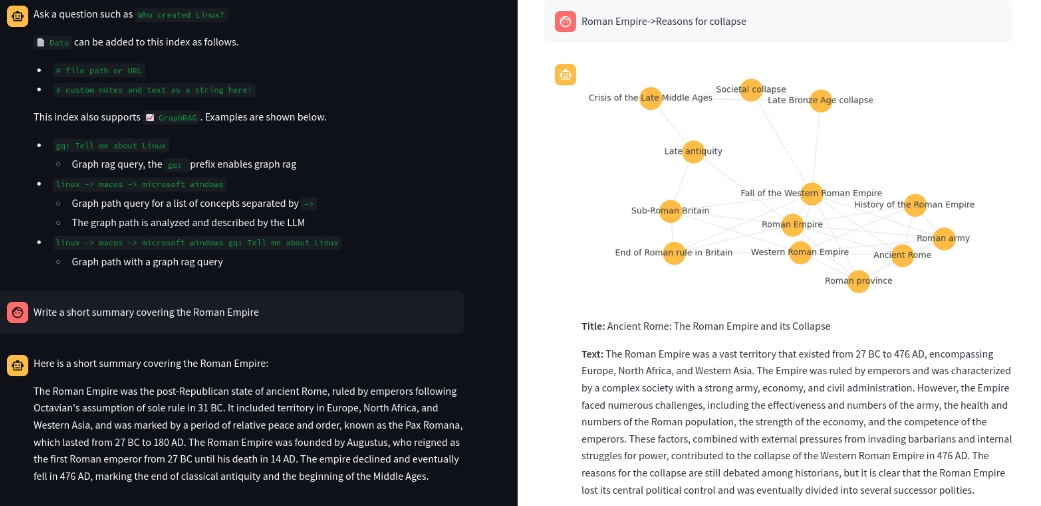
向量 RAG
此方法通过向量搜索找到与用户输入最相关的前 N 个匹配项,并将这些匹配项传递给 LLM,并返回答案。
示例查询:Who created Linux?
图 RAG
图 RAG 使用知识图或语义图来生成上下文,而不是向量搜索。
方法包括:
-
图查询(
gq:前缀):从向量搜索开始,然后通过图网络扩展。 示例:gq: Tell me about Linux -
图路径查询:匹配概念列表,并通过图路径遍历创建相关上下文。 示例:
linux -> macos -> microsoft windows -
组合查询:先进行图路径查询,再在该路径上下文内进行图查询。 示例:
linux -> macos -> microsoft windows gq: Tell me about Linux
数据添加到索引
可以通过以下方式添加数据:
| 方法 | 图示 |
|---|---|
文件路径或 URL # 文件路径或URL |
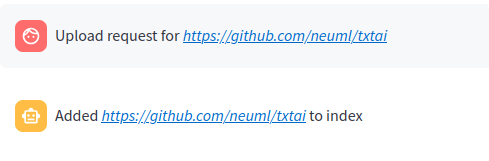 |
自定义备注和文本 # 自定义备注和文本 |
 |
示例:# txtai is an all-in-one embeddings database 会在 Embeddings 数据库中创建一个新条目。
配置参数
应用程序提供多个环境变量用于配置:
| 变量 | 描述 | 默认值 |
|---|---|---|
| TITLE | 应用主标题 | 🚀 RAG with txtai |
| LLM | LLM 模型设置 | Mistral-7B-OpenOrca-AWQ |
| EMBEDDINGS | Embeddings 数据库路径 | neuml/txtai-wikipedia-slim |
| DATA | 输入数据目录(可选) | 无 |
| TOPICSBATCH | 批处理主题 LLM 查询(可选) | 无 |
Docker 运行示例:
docker run -d --gpus=all -it -p 8501:8501 -e LLM=hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4 neuml/rag
docker run -d --gpus=all -it -p 8501:8501 -e EMBEDDINGS=neuml/arxiv neuml/rag
docker run -d --gpus=all -it -p 8501:8501 -e DATA=/data/path -v local/path:/data/path neuml/rag
使用场景
- 知识问答系统:通过 RAG 检索和生成结合的方法,为特定主题提供精确回答。
- 内容生成:利用丰富的上下文和知识图,让 LLM 生成准确且上下文相关的内容。
- 文档理解:从大量文档中提取相关信息并进行有效回答。
通过上述功能和场景,RAG with txtai 提供了一个强大的框架,用于实现更为智能和准确的信息检索与生成应用。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621