
DIVA
DIVA(DIffusion model as a Visual Assistant)是一种通过生成模型的反馈来优化CLIP(Contrastive Language-Image Pretraining)模型视觉表现的后处理方法。具体来说,DIVA利用文本到图像的扩散模型生成的反馈,来优化CLIP的图像表示,仅需要图像数据而不需要对应的文本数据。实验表明,DIVA在诸多图像分类和检索基准测试中提升了CLIP模型的性能,同时增强了多模态理解和分割任务中的表现,而仍保持了CLIP强大的零样本能力。
DIVA的使用场景:
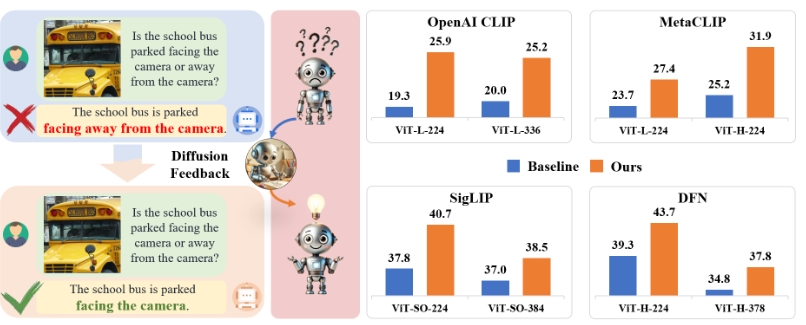
- 图像分类与检索:在多达29个图像分类和检索基准测试中,DIVA提升了模型的表现。
- 多模态理解:在MMVP-VLM基准测试中,DIVA显著提高了CLIP模型对细粒度视觉能力的评估表现。
- 图像分割:DIVA可以提升视觉模型在图像分割任务中的性能。
- 生成模型辅助:DIVA利用生成模型的反馈,优化基于文本和图像的预训练模型的视觉表示。
安装与准备工作:
- 使用
git clone命令克隆DIVA仓库,并安装所需的Python包。 - 下载并准备预训练权重,涉及的模型包括OpenAI ViT-L-14、MetaCLIP、SigLIP、DFN和Stable Diffusion模型。
- 修改CLIP、OpenCLIP和timm包中一些源代码以适应DIVA的条件设计。
训练与评估:
准备工作完成后,可以通过运行相应的脚本(如DIVA_for_OpenAICLIP.sh)来启动训练。
可视化:
DIVA还提供了性能提升的可视化结果,展示在多个基准测试中的改善效果。
这是一个综合的处理方法,旨在通过扩散模型的反馈来克服CLIP模型在视觉表现上的不足,适用于各种多模态理解和图像处理任务。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621