
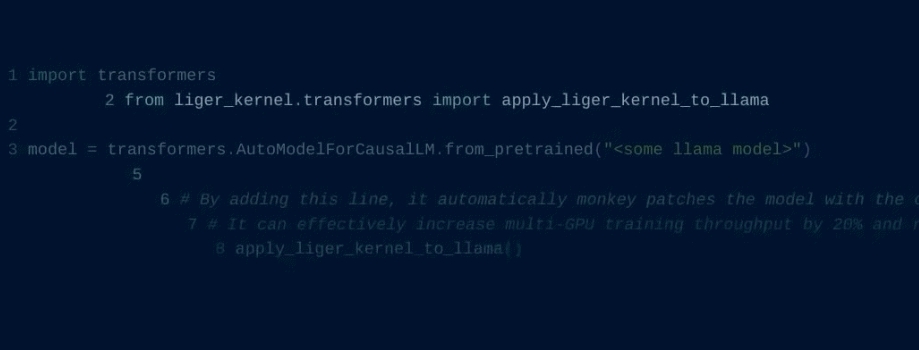
Liger Kernel
Liger Kernel 是一个专门为大型语言模型(LLM)训练设计的 Triton kernel 库,其目标是提高训练效率。Liger Kernel 提供了一系列优化操作,使得多 GPU 训练的吞吐量提高了 20%,同时内存使用减少了 60%。该库包括兼容 Hugging Face 的多个模块,如 RMSNorm、RoPE、SwiGLU、CrossEntropy 等,支持与 Flash Attention、PyTorch FSDP 和 Microsoft DeepSpeed 等训练框架无缝集成。
主要特点
- 高效性:通过内核融合、原地替换和分块技术,Liger Kernel 在训练时显著提高了效率。
- 准确性:实现了严格的单元测试,确保前向和反向传播的计算结果是精确的。
- 轻便:只依赖必要的库(Torch 和 Triton),避免了依赖管理的复杂性。
- 多 GPU 支持:兼容多种分布式训练策略,能够最大化 GPU 的训练效率。
使用场景
- 研究人员:希望使用高效、可靠的内核进行前沿实验。
- 机器学习从业者:关注优化 GPU 训练效率,负担高性能内核。
- 初学者:希望学习如何编写可靠的 Triton 内核,以增强训练效率。
Liger Kernel 可以通过简单的代码更换原有模型中的某些层,或使用其提供的模块组合出新的模型,极大地提升了训练的灵活性和性能。

广告:私人定制视频文本提取,字幕翻译制作等,欢迎联系QQ:1752338621